Nvidia: Hiệu suất AI của H100 cải thiện tới 54% nhờ tối ưu hóa phần mềm
Nvidia vừa công bố một số con số hiệu suất mới cho GPU điện toán H100 của họ trong MLPerf 3.0, phiên bản mới nhất của một điểm chuẩn nổi bật cho khối lượng công việc học sâu. Bộ xử lý Hopper H100 không chỉ vượt qua người tiền nhiệm A100 về phép đo thời gian đào tạo mà còn đạt được hiệu suất nhờ tối ưu hóa phần mềm. Ngoài ra, Nvidia cũng tiết lộ những so sánh hiệu suất ban đầu của GPU máy tính nhỏ gọn L4 của họ với GPU T4 tiền nhiệm.
Nvidia lần đầu tiên công bố kết quả kiểm tra H100 thu được trong điểm chuẩn MLPerf 2.1 vào tháng 9 năm 2022, tiết lộ rằng GPU điện toán hàng đầu của họ có thể đánh bại người tiền nhiệm A100 tới 4,3–4,4 lần trong các khối lượng công việc suy luận khác nhau. Các con số hiệu suất mới được công bố thu được trong MLPerf 3.0 không chỉ xác nhận rằng H100 của Nvidia nhanh hơn A100 của nó (không có gì ngạc nhiên), mà còn khẳng định rằng nó cũng nhanh hơn đáng kể so với bộ xử lý Xeon Platinum 8480+ (Sapphire Rapids) mới ra mắt gần đây của Intel cũng như của NeuChips Giải pháp ReccAccel N3000 và Cloud AI 100 của Qualcomm trong một loạt khối lượng công việc
Các khối lượng công việc này bao gồm phân loại hình ảnh (ResNet 50 v1.5), xử lý ngôn ngữ tự nhiên (BERT Large), nhận dạng giọng nói (RNN-T), hình ảnh y tế (3D U-Net), phát hiện đối tượng (RetinaNet) và đề xuất (DLRM). Nvidia đưa ra quan điểm rằng GPU của họ không chỉ nhanh hơn mà còn hỗ trợ tốt hơn trong ngành ML — một số khối lượng công việc không thành công trên các giải pháp cạnh tranh.
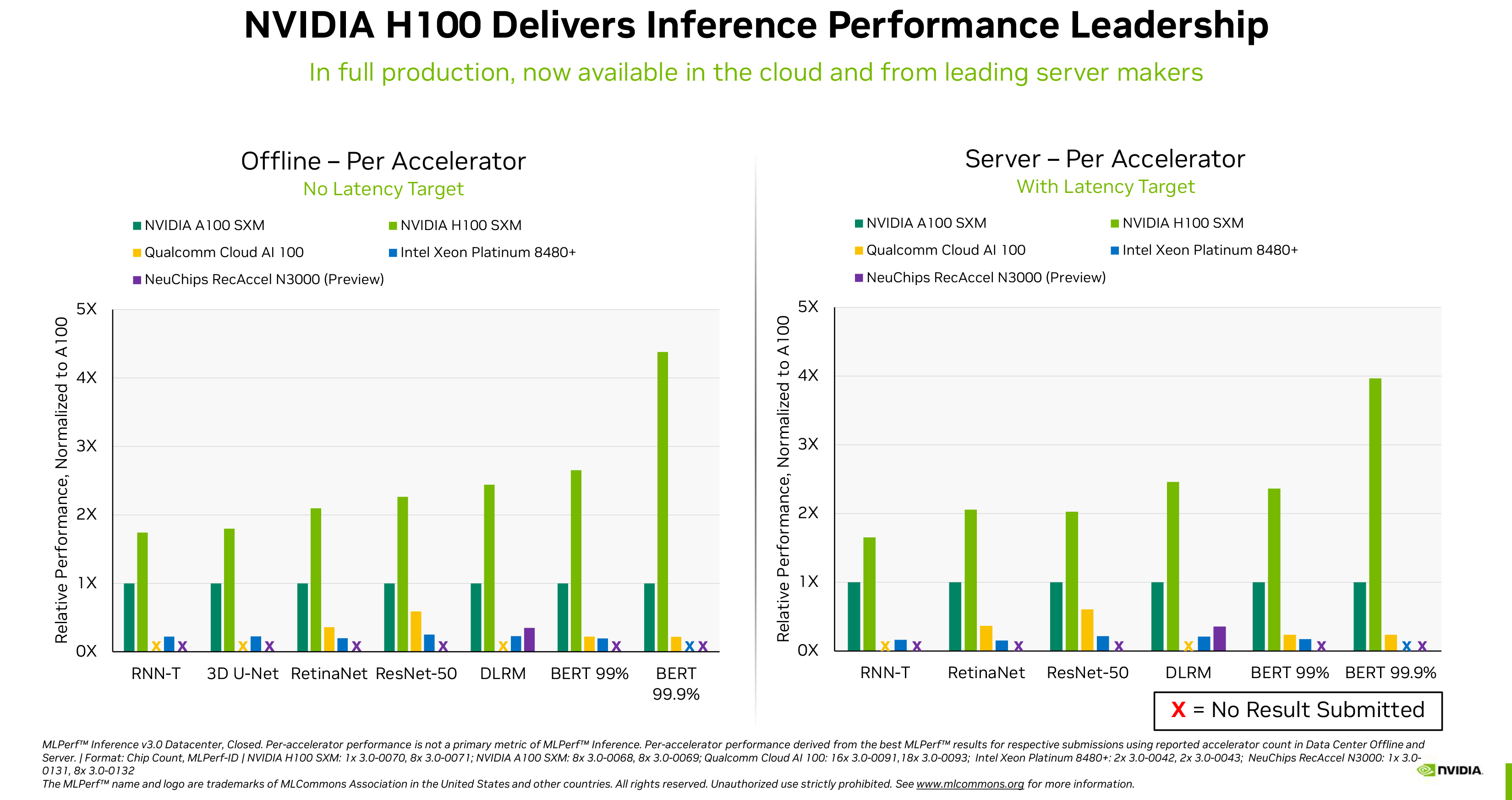
Tuy nhiên, có một nhược điểm với những con số do Nvidia công bố. Các nhà cung cấp có tùy chọn gửi kết quả MLPerf của họ theo hai loại: đóng và mở. Trong danh mục đóng, tất cả các nhà cung cấp phải chạy các mạng thần kinh tương đương về mặt toán học, trong khi ở danh mục mở, họ có thể sửa đổi mạng để tối ưu hóa hiệu suất cho phần cứng của họ. Các con số của Nvidia chỉ phản ánh danh mục đóng, do đó, các tối ưu hóa mà Intel hoặc các nhà cung cấp khác có thể giới thiệu để tối ưu hóa hiệu suất phần cứng của họ không được phản ánh trong các kết quả nhóm này.
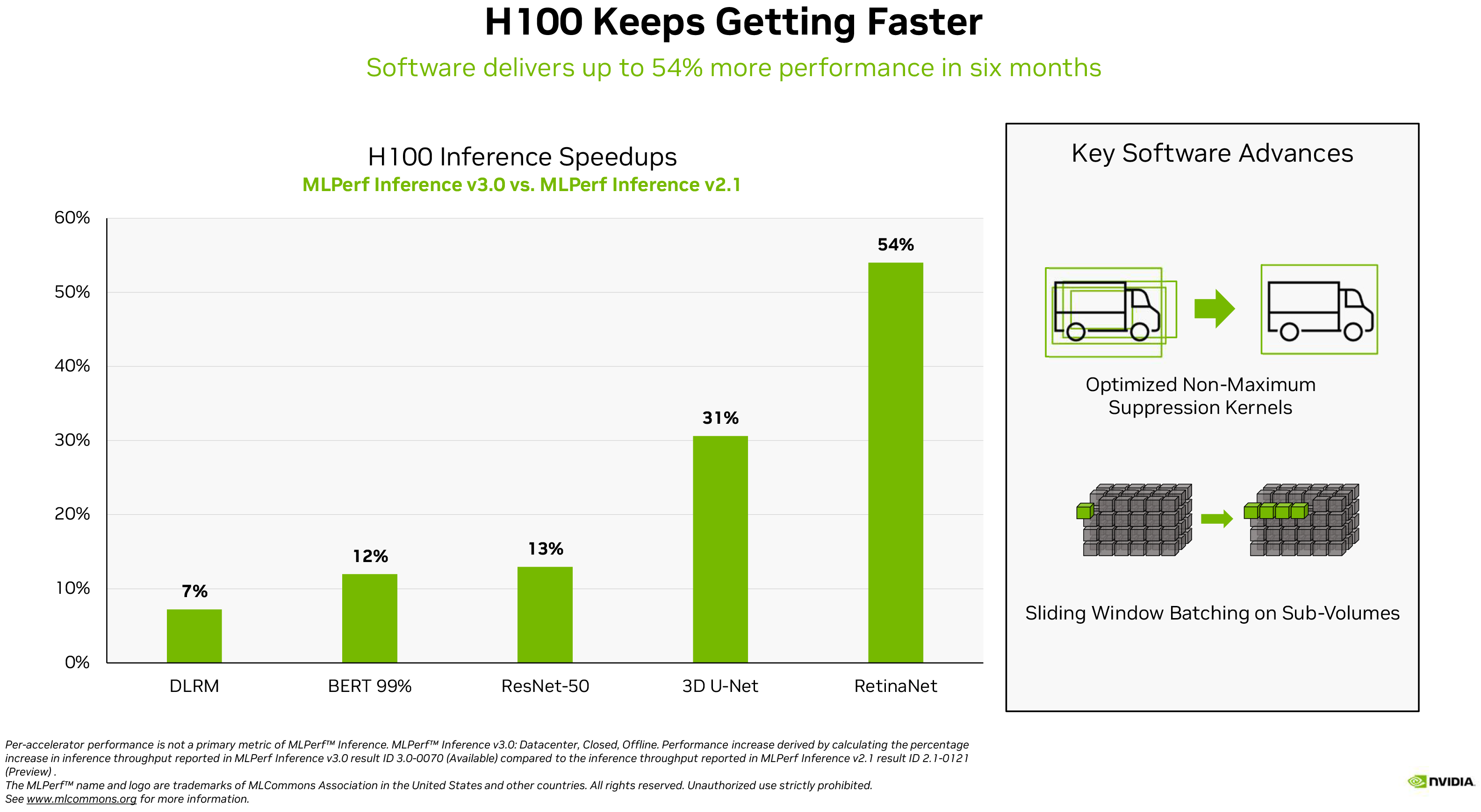
Tối ưu hóa phần mềm có thể mang lại lợi ích to lớn cho phần cứng AI hiện đại, như ví dụ của chính Nvidia cho thấy. H100 của công ty đã tăng từ 7% khối lượng công việc đề xuất lên 54% khối lượng công việc phát hiện đối tượng với MLPerf 3.0 so với MLPerf 2.1, đây là một mức tăng hiệu suất đáng kể.
Đề cập đến sự bùng nổ của ChatGPT và các dịch vụ tương tự, Dave Salvator, Giám đốc AI, Đo điểm chuẩn và Đám mây, tại Nvidia, viết trong một bài đăng trên blog: “Tại thời điểm AI của iPhone này, hiệu suất suy luận là rất quan trọng… Học sâu hiện đang được được triển khai gần như ở khắp mọi nơi, thúc đẩy nhu cầu vô độ về hiệu suất suy luận từ sàn nhà máy đến các hệ thống đề xuất trực tuyến.”
Ngoài việc tái khẳng định rằng H100 của họ là vua hiệu suất suy luận trong MLPerf 3.0, công ty cũng đã hé lộ về hiệu suất của GPU tính toán L4 dựa trên AD104 được phát hành gần đây. (mở trong tab mới). Thẻ GPU điện toán được hỗ trợ bởi Ada Lovelace này có hệ số dạng cấu hình thấp một khe cắm để phù hợp với bất kỳ máy chủ nào, nhưng nó mang lại hiệu suất khá đáng gờm: lên tới 30,3 FP32 TFLOPS cho điện toán thông thường và lên tới 485 FP8 TFLOPS (với độ thưa thớt ).

Nvidia chỉ so sánh L4 của mình với một trong những GPU trung tâm dữ liệu nhỏ gọn khác của họ, T4. Phiên bản thứ hai dựa trên GPU TU104 có kiến trúc Turing từ năm 2018, do đó, không có gì ngạc nhiên khi GPU mới nhanh hơn 2,2–3,1 lần so với phiên bản tiền nhiệm trong MLPerf 3.0, tùy thuộc vào khối lượng công việc.
Salvator viết: “Bên cạnh hiệu suất AI xuất sắc, GPU L4 còn mang đến khả năng giải mã hình ảnh nhanh hơn tới 10 lần, xử lý video nhanh hơn tới 3,2 lần, đồ họa nhanh hơn 4 lần và hiệu suất kết xuất thời gian thực”.
Không còn nghi ngờ gì nữa, kết quả điểm chuẩn của GPU điện toán H100 và L4 của Nvidia — đã được cung cấp bởi các nhà sản xuất hệ thống và nhà cung cấp dịch vụ đám mây lớn — trông rất ấn tượng. Tuy nhiên, hãy nhớ rằng chúng tôi đang xử lý các số điểm chuẩn do chính Nvidia công bố chứ không phải các bài kiểm tra độc lập.