Lõi 72 Arm V9.0, Bộ nhớ đệm L3 117 MB, 68 Làn PCIe Thế hệ 5, Quy trình TSMC 4N & TDP 500W
NVIDIA đã tiết lộ các chi tiết mới về các kết nối với nhau của CPU Grace, Orin SOC và chip NVLINK trong Hot Chips 34.
Nắp phá vỡ CPU Grace của NVIDIA, có 72 lõi v9.0 trên mỗi chip, 117 MB bộ nhớ đệm L3, 68 làn thế hệ 5, Tất cả đều có trên nút xử lý TSMC 4N
NVIDIA lần đầu tiên công bố CPU Grace và thiết kế Superchip tương ứng tại GTC 2022. CPU Grace là bộ xử lý đầu tiên của NVIDIA dựa trên kiến trúc Arm tùy chỉnh sẽ hướng đến phân khúc máy chủ / HPC. CPU này có hai cấu hình Superchip, một mô-đun Grace Superchip với hai CPU Grace và một Grace + Hopper Superchip với một CPU Grace được kết nối với GPU Hopper H100.

Một số điểm nổi bật chính của Grace bao gồm:
- CPU hiệu suất cao cho HPC và điện toán đám mây
- Thiết kế siêu chip với tối đa 144 lõi CPU Arm v9
- LPDDR5x đầu tiên trên thế giới có Bộ nhớ ECC, tổng băng thông 1TB / s
- SPECrate2017_int_base trên 740 (ước tính)
- Giao diện mạch lạc 900 GB / s, nhanh hơn gấp 7 lần so với PCIe Gen 5
- Gấp 2 lần mật độ đóng gói của các giải pháp dựa trên DIMM
- 2 lần hiệu suất trên mỗi watt của CPU hàng đầu hiện nay
- Chạy tất cả các nền tảng và ngăn xếp phần mềm NVIDIA, bao gồm RTX, HPC, AI và Omniverse
Là CPU máy chủ đầu tiên của NVIDIA, Grace có 72 lõi Arm v9.0 hỗ trợ SVE2 và nhiều phần mở rộng ảo hóa khác nhau như Ảo hóa lồng nhau và S-EL2. CPU được chế tạo trên nút quy trình 4N của TSMC, một phiên bản được tối ưu hóa của nút quy trình 5nm được sản xuất dành riêng cho NVIDIA.

Grace được thiết kế để ghép nối và như vậy, một trong những khía cạnh quan trọng nhất của thiết kế là kết nối C2C (Chip-To-Chip) của nó. Grace đạt được điều này nhờ NVLINK được sử dụng để tạo Superchips và loại bỏ tất cả các nút thắt cổ chai có liên quan đến cấu hình cross-socket điển hình.
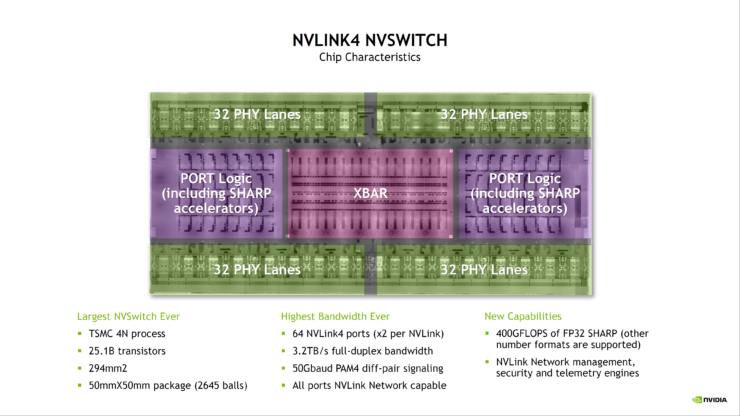
Kết nối C2C NVLINK cung cấp băng thông hai chiều thô 900 GB / s (băng thông tương tự như công tắc GPU sang GPU NVLINK trên Hopper), đồng thời chạy ở giao diện năng lượng rất thấp chỉ 1,3 pJ / bit hoặc hiệu quả hơn 5 lần so với Giao thức PCIe.
CPU NVIDIA Grace có cấu trúc đồng tiền có thể mở rộng với thiết kế bộ đệm phân tán. Con chip này có băng thông hai phần lên đến 3.225 TB / s, có thể mở rộng vượt quá 72 lõi (144 trên Superchip), tích hợp 117 MB bộ nhớ đệm L3 và có tính năng hỗ trợ phân vùng và giám sát bộ nhớ Arm (MPAM). Grace cũng cho phép một kiến trúc bộ nhớ thống nhất với các bảng trang được chia sẻ. Hai NVIDIA Grace + Hopper Superchip có thể được kết nối với nhau thông qua NVSwitch và một CPU Grace trên một Superchip có thể giao tiếp trực tiếp với GPU trên chip kia hoặc thậm chí truy cập VRAM của nó ở tốc độ NVLINK gốc.
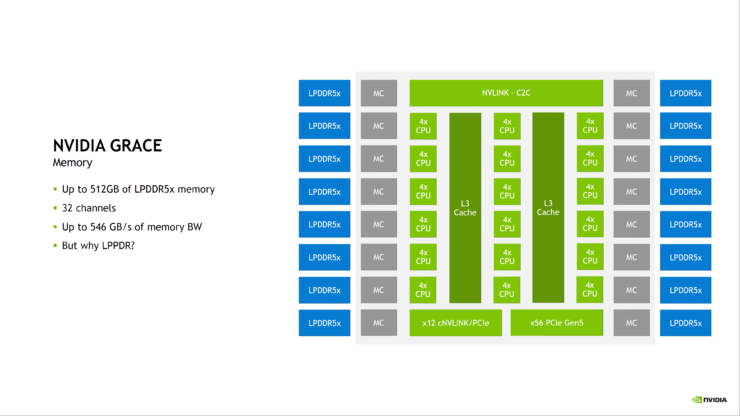
Xem xét kỹ hơn thiết kế bộ nhớ của Grace, NVIDIA đang sử dụng lên đến 512 GB LPDDR5X trên 32 kênh, cung cấp băng thông bộ nhớ lên đến 546 GB / giây. NVIDIA tuyên bố rằng LPDDR5X cung cấp giá trị tốt nhất khi lưu ý đến yêu cầu về băng thông, chi phí và điện năng tổng thể. Đối với I / O, bạn nhận được 68 làn PCIe Gen 5.0, bốn trong số đó có thể được sử dụng cho các liên kết x16 với tốc độ 128 GB / s, và hai làn còn lại được sử dụng cho MISC. Ngoài ra còn có 12 làn đường NVLINK gắn kết được chia sẻ với hai liên kết PCIe x16 Gen 5.
Đối với TDP, Siêu vi mạch NVIDIA Grace (Chỉ dành cho CPU) được tối ưu hóa cho hiệu suất lõi đơn và cung cấp băng thông bộ nhớ lên đến 1 TB / s và TDP 500W cho cấu hình chip 144 lõi kép. Chúng tôi đã đưa các con số vào quan điểm trong một bài viết trước có thể được nhìn thấy bên dưới:
Bây giờ, đây không phải là sự khác biệt lớn về hiệu suất nhưng những gì chúng tôi thực sự muốn thấy là các chỉ số hiệu suất. Grace SUPERCHIPS được đánh giá ở mức khoảng 500W trong khi mỗi chip AMD EPYC 7763 có TDP là 280W, vì vậy hai trong số chúng sẽ vào khoảng 560W và chúng tôi sẽ không thêm công suất hệ thống bổ sung trong khi con số 500W của NVIDIA là cho toàn bộ gói GRACE SUPERCHIP.
NVIDIA tuyên bố rằng Grace là một bộ xử lý chuyên biệt cao nhắm mục tiêu các khối lượng công việc như đào tạo các mô hình NLP thế hệ tiếp theo có hơn 1 nghìn tỷ tham số. Khi được kết hợp chặt chẽ với GPU NVIDIA, hệ thống dựa trên CPU Grace sẽ mang lại hiệu suất nhanh hơn 10 lần so với hệ thống dựa trên NVIDIA DGX hiện đại nhất hiện nay, chạy trên CPU x86.

Chắc chắn sẽ rất thú vị khi thấy cách các CPU Grace xếp chồng lên nhau với chip x86 nhưng vào thời điểm phát hành, chúng sẽ cạnh tranh với CPU Genoa của AMD và Sapphire Rapids của Intel. Các CPU NVIDIA Grace được lên kế hoạch sử dụng trong siêu máy tính ATOS như được báo cáo tại đây.