AMD đã công bố hai card đồ họa RDAN3 chuyên nghiệp hoàn toàn mới có bộ nhớ lên tới 48GB và bộ làm mát kiểu quạt gió. Hai mô hình bao gồm Radeon Pro W7900 và Radeon Pro W7800, với 96 và 70 đơn vị tính toán tương ứng. Cả hai GPU đều được thiết kế cho những người sáng tạo nội dung và các chuyên gia yêu cầu khả năng tính toán và dung lượng bộ nhớ ở mức cao để xử lý khối lượng công việc hiệu năng cao.
Radeon Pro W7900 hiện là sản phẩm cao cấp nhất trong sê-ri, trang bị 96 CU, 12.288 lõi đổ bóng và bộ nhớ 48GB hoạt động trên bus rộng 384-bit cho băng thông bộ nhớ cao nhất là 864GB/giây. AMD đánh giá GPU này lên tới 61 TFLOPS hiệu suất FP32 với tổng công suất định mức của bo mạch là 295W. GPU này là phiên bản Pro của RX 7900 XTX, có cùng số lượng lõi và độ rộng bus bộ nhớ như đối tác tiêu dùng của nó. Tuy nhiên, điểm khác biệt đáng kể nhất với W7900 là dung lượng bộ nhớ khủng 48GB, giúp máy thực thi công việc chuyên nghiệp hơn nhiều so với 7900 XTX.
Tốc độ xung nhịp chưa được biết, nhưng dự kiến xung nhịp cơ bản và xung tăng cường sẽ thấp hơn đáng kể so với RX 7900 XTX tham chiếu do định mức công suất bo mạch thấp hơn của W7900 và tích hợp bộ làm mát kiểu quạt gió ba khe.
Radeon Pro W7800 là một sản phẩm tầm trung có 70CU, 8960 lõi đổ bóng và bus 256 bit có bộ nhớ 32GB và băng thông bộ nhớ 576GB/giây. AMD đánh giá GPU này ở mức tối đa 45 TFLOPS của hiệu năng tính toán FP32, với định mức TBP là 260W. Đây là GPU tầm trung với thông số kỹ thuật GPU được hạ cấp toàn bộ trên toàn bộ bảng, với ít lõi đổ bóng hơn so với RX 7900 XT. Tuy nhiên, GPU vẫn cung cấp rất nhiều sức mạnh tính toán và bộ nhớ video 32 GB, sẽ tối ưu cho khối lượng công việc nhạy cảm với bộ nhớ.
AMD đã không đề cập đến tốc độ xung nhịp và loại bộ làm mát, nhưng hy vọng thẻ này sẽ có bộ làm mát kiểu quạt gió như W7900, mặc dù có hệ số dạng khe cắm kép được cắt giảm.
Phần thú vị của W7800 là chúng ta có thể xem trước biến thể dành cho người tiêu dùng có thể trông như thế nào. W7800 là GPU tầm trung RDNA3 đầu tiên mà chúng tôi thấy từ AMD cho đến nay và nó cho biết kích thước bus bộ nhớ và số lượng lõi mà AMD đang nhắm mục tiêu cho các GPU tầm trung cao cấp của mình. Nếu số lượng lõi và thông số bộ nhớ khớp hoàn hảo, như với W7900 và RX 7900 XTX, thì chúng ta có thể mong đợi RX 7800 hoặc 7800 XT trong tương lai có 8960 lõi và bus 256 bit.
Radeon Pro W7900 và W7800 hiện đã có sẵn và các thẻ này sẽ bắt đầu xuất hiện trong các hệ thống OEM và SI vào nửa cuối năm nay. W7900 sẽ có giá 3.999 USD và W7800 sẽ có giá 2.499 USD.
Người sáng lập kiêm Giám đốc điều hành của Nvidia, Jensen Huang, đã được phát hiện đang thích nghi ở Đài Bắc trước thềm triển lãm Computex lớn. Khác xa với cuộc sống tại gia hiện đã ổn định của mình ở khu vực Billionaire’s Row của San Francisco, ông chủ công nghệ người Mỹ gốc Đài Loan đang tận hưởng khung cảnh, âm thanh (và mùi vị?) Không khí của một trong nhiều khu chợ đêm của Đài Bắc. Huang sống ở Đài Loan cho đến năm 9 tuổi thì gia đình anh chuyển đến Portland, Oregon.
Người đồng sáng lập Nvidia, Jensen Huang (黃仁勳) đi bộ qua chợ đêm của Đài Bắc đêm qua khi vốn hóa thị trường của Nvidia đạt 1T.#taipei #taiwan pic.twitter.com/8WZSv1k2p826 Tháng Năm, 2023
Xem thêm
Trong dòng tweet được nhúng ở trên, bạn có thể thấy Huang đang cân nhắc về trái cây sấy khô ở chợ đêm. CW Lin, người đã chụp bức ảnh, đã trầm ngâm khi nhìn thấy vị CEO đi qua một khu chợ khiêm tốn như vậy với chiếc túi xách trên tay.
Đầu tuần này, chúng tôi đã báo cáo về đợt tăng giá cổ phiếu bất thường của Nvidia. Suy đoán của nhà đầu tư về vận may của các doanh nghiệp công nghệ AI đã thúc đẩy sự tăng trưởng định giá bùng nổ này và Nvidia là một trong những trụ cột của doanh nghiệp này. Nắm giữ 3,51% cổ phần của công ty (hơn 86 triệu cổ phiếu), giá trị tài sản ròng của Huang đã tăng vọt từ hơn 26 tỷ đô la một hai tuần trước lên hơn 34 tỷ đô la ngày nay.
Hình ảnh Huang của CW Lin dường như không cho thấy bằng chứng về chi tiết bảo mật với Giám đốc điều hành Nvidia. Tuy nhiên, báo cáo tài chính mới nhất do Nvidia công bố cho thấy chi phí an ninh của giám đốc điều hành đã tăng hơn 750% trong năm ngoái, với tổng trị giá 700.000 USD. Anh ấy không cần nhân viên an ninh ở Đài Bắc, hay họ giỏi đến mức chúng tôi thậm chí không biết họ ở đó?
Lần cuối cùng chúng tôi nhìn thấy Huang trên đường phố Đài Bắc là vào tháng 11 năm ngoái khi anh ấy bị bắt gặp đang ‘quay video’ một số ca sĩ karaoke đang bối rối và yêu cầu một bài hát của Lady Gaga. Anh ấy đã ở thành phố để tham dự WirForce 2022 eSports Carnival.
Vào thứ Hai, Giám đốc điều hành của Nvidia sẽ lên sân khấu tại Computex 2023 để đưa ra một bài phát biểu quan trọng đặc biệt. Là một chương trình dành cho người tiêu dùng tập trung vào PC, chúng tôi hy vọng sẽ được nghe một số thông tin chi tiết thú vị về các công nghệ phần cứng và phần mềm GeForce mới và sắp ra mắt. Tuy nhiên, trong báo cáo tài chính gần đây nhất đã làm rõ rằng trò chơi hiện mang lại khoảng một nửa doanh thu mà hoạt động kinh doanh trung tâm dữ liệu tạo ra.
Một bài đăng trên blog gần đây của TinyApps nêu bật sự xuất hiện của một công cụ ngoại tuyến có thể kích hoạt thành công cài đặt Windows XP. Công cụ mới an toàn hơn các giải pháp trước đây, nó không phải là bản bẻ khóa và nó hoạt động hoàn toàn ngoại tuyến. Nó không yêu cầu kết nối trực tuyến (một lĩnh vực rủi ro đối với các máy Win XP), đây là một phần thưởng đáng kể.
Windows XP được giới thiệu vào tháng 10 năm 2001 và nhiều người dùng PC hiện đại sẽ hoặc là đã đến với thời kỳ trị vì của nó hoặc hoàn toàn thích thú với bản nâng cấp từ các loại DOS/Windows thế hệ trước. Do đó, Windows XP có một vị trí đặc biệt trong trái tim của nhiều người đam mê PC và những người tự làm. Vì vậy, giờ đây, điều tự nhiên là những người dùng này đôi khi sẽ tìm cách tập hợp các bản cài đặt Windows XP phần cứng cũ hoặc ảo hóa lại với nhau để có được những trò chơi cổ điển cao cấp. Đây là lúc công cụ xp_activate32.exe được chia sẻ bởi retroreviewyt xuất hiện.
Công cụ kích hoạt được liên kết ở trên (18 KB) được cho là một “tiện ích kích hoạt điện thoại”, đã được đóng gói thành một tệp thực thi nhỏ gọn để kích hoạt Windows XP hoàn toàn ngoại tuyến. Có thể hiểu được rằng Microsoft đã tắt các máy chủ kích hoạt Windows XP nhiều năm trước, vì vậy công cụ này cho phép những người mày mò kích hoạt một cách an toàn mà không gặp nhiều phiền phức.
(Nguồn: Tương lai)
Những nguy hiểm khi trực tuyến vào năm 2023 bằng Windows XP đã được làm rõ trong các cuộc thảo luận về công cụ mới này trên Reddit. Tuy nhiên, vì công cụ này cho phép kích hoạt hệ điều hành mà không cần bất kỳ kết nối internet nào nên nó giúp tránh hệ thống XP mới được đúc của bạn bị tấn công do bất kỳ sai sót/lỗ hổng nào.
Nếu sau những điều trên, bạn không chắc tại sao mình muốn chạy Windows XP vào năm 2023 hoặc bất kỳ thời điểm nào trong tương lai, thì một vài gợi ý được cung cấp bên dưới:
Sử dụng công cụ hệ thống, ứng dụng hoặc trò chơi chưa từng được nâng cấp để tương thích với HĐH Windows hiện được hỗ trợ,
Sử dụng phần cứng cũ không được nền tảng hiện tại và/hoặc HĐH Windows hiện đại hỗ trợ,
Đắm mình trong một số nghiên cứu phần cứng / phần mềm cũ hơn,
Để giải quyết sự tò mò, hoài niệm, hoặc chỉ để cho vui.
Nếu bạn có ý định cài đặt và sử dụng Windows XP, hãy đề phòng. Ngoài hệ điều hành và ngăn xếp PCP/IP còn nhiều lỗ hổng đã biết chưa được vá, sẽ rất khó (nhưng không phải là không thể) để có được các yếu tố cần thiết trực tuyến an toàn như trình duyệt và phần mềm chống vi-rút. Do đó, nhiều người sẽ thích giữ hệ điều hành ngoại tuyến hơn và sử dụng phần mềm cũ (và phần cứng?) Trong kho lưu trữ của họ.
Nếu bạn vẫn đang bỏ lỡ kỷ nguyên Windows XP, hãy xem một số báo cáo (tương đối) khác gần đây, như rò rỉ mã nguồn Windows XP, cống nạp Windows XP của Raspian và tin tức về việc ai đó đã cài đặt Windows XP chạy trên chuỗi khối Bitcoin SV.
Những người quan tâm hơn đến việc sử dụng các HĐH Windows cũ hơn, chẳng hạn như Windows 95, để theo đuổi phong cách cổ điển của họ có thể yêu cầu ChatGPT tìm khóa sê-ri vì thuật toán đơn giản hơn nhiều.
Thẻ thiết kế tham chiếu RX 7600 của AMD dường như có lỗi thiết kế có thể ảnh hưởng đến một số người dùng, đặc biệt là ngăn họ cắm hoàn toàn đầu nối cấp nguồn phụ 8 chân cần thiết. Chúng tôi không gặp sự cố với các hệ thống thử nghiệm và PSU của mình (thẻ hoạt động trên cả ba PC với ba nguồn điện khác nhau), nhưng như TechPowerUp đã lưu ý, một số đầu nối 6+2 chân có thể không vừa do có tấm che xung quanh.
Nếu bạn đang tìm mua thẻ tham chiếu Radeon RX 7600 “Made By AMD” (MBA), trước tiên bạn nên xác nhận rằng các đầu nối PSU của bạn sẽ phù hợp. Trường hợp xấu nhất, bạn có thể mua cáp mở rộng 8 chân, nhưng những thứ đó có thể làm hỏng tính thẩm mỹ của bản dựng của bạn. Đừng lộn xộn chi, anh bạn!
Nguyên nhân sâu xa là do thiếu khe hở xung quanh đầu nối 8 chân trên thẻ, với một lỗ nhỏ có thể không vừa với một số đầu nối 6+2 chân đạt tiêu chuẩn với hầu hết các bộ nguồn. Vấn đề cụ thể là ổ khóa cho hai chân bổ sung đó có thể bị tấm ốp lưng chặn lại, ngăn không cho cắm đầy đủ đầu nối nguồn.
Hình ảnh 1 của 2
Người dùng có thể gặp khó khăn khi cắm hoàn toàn các đầu nối nguồn PCIe 6+2 chân do lỗi thiết kế tấm ốp lưng quá dài của AMD. (Nguồn: TechPowerUp!)
Gờ bổ sung có trong các đầu nối nguồn 6+2 chân ngăn không cho cáp vào hoàn toàn. (Nguồn: TechPowerUp!)
Theo như chúng tôi có thể nói, việc không lắp đầy đủ đầu nối đã không gây ra bất kỳ “sự cố” nào, không giống như NVIDIA và các đầu nối RTX 4090 của nó. Điều đó có thể là do lỗi thiết kế RX 7600 của AMD có nghĩa là đầu nối nguồn sẽ vừa hoặc không. Người dùng phải luôn đảm bảo mọi đầu nối nguồn được cắm hoàn toàn và ít nhất cũng dễ dàng xác nhận bằng mắt thường đầu nối 6+2 của bạn có được lắp đúng cách hay không. Trong mọi trường hợp, GPU 165W sẽ không gây quá nhiều áp lực cho hệ thống phụ cung cấp năng lượng, không giống như RTX 4090 với TDP 450W.
TechPowerUp! nói rằng chỉ 20% đầu nối nguồn PCIe mà họ sở hữu không tương thích với thiết kế RX 7600, nhưng thật khó để đánh giá mức độ quan trọng của điều đó. Khi đề cập đến vấn đề này, Igor’s Lab cho biết rằng cáp cấp nguồn NVIDIA PCAT (một công cụ dùng để đo điện năng) có thể không vừa. (Cáp của chúng tôi phù hợp, theo hồ sơ.) Cáp gốc từ bộ nguồn Seasonic cũng có thể bị ảnh hưởng.
AMD có kế hoạch bán thẻ MBA RX 7600 tham khảo của mình, mặc dù hiện tại nó được liệt kê là sắp ra mắt. Hiện tại, những mô hình này chỉ được gửi để đánh giá theo như chúng tôi biết. AMD có khả năng có thể sửa thiết kế của tấm ốp lưng cho các lần sản xuất trong tương lai, nhưng cách khắc phục tạm thời sẽ là bao gồm một bộ mở rộng 8 chân trong mỗi lần mua hàng. Nếu bạn dự định mua thẻ RX 7600 và vấn đề ảnh hưởng đến bạn, hãy liên hệ với kênh hỗ trợ của AMD — hoặc chỉ mua một mẫu không có MBA. Hiện hãng chưa có bình luận chính thức nào về vấn đề này.
Các quả mâm xôi là một cú hích lớn trong thế giới trò chơi cổ điển và đã được chứng minh là cực kỳ linh hoạt khi nói đến cách nó có thể được thực hiện. Hôm nay chúng tôi đang chia sẻ một tác phẩm tuyệt đẹp của không ai khác ngoài Zarcadeuk, người đã tập hợp một Bộ Game Boy Advance SPđược đặt tên là Mame Boy Advance SP, được thiết kế để hỗ trợ cả Raspberry Pi Zero và Raspberry Pi Zero 2 W. Bộ công cụ này có mọi thứ bạn cần để bắt đầu ngoại trừ Raspberry Pi, các nút và vỏ.
Đây không phải là lần đầu tiên chúng tôi chia sẻ công việc của Zarcadeuk. Anh ấy có rất nhiều bộ trò chơi cổ điển tích hợp Raspberry Pi và chúng tôi muốn khoe chúng khi có thể. Trong quá khứ, anh ấy đã tập hợp một ấn tượng Bộ dụng cụ trò chơi Sega hỗ trợ Raspberry Pi Compute Module 4 và một bộ khác cho bản gốc cậu bé trò chơi sử dụng Raspberry Pi Zero.
Bộ sản phẩm Mame Boy Advance SP mới gần như đã sẵn sàng. Theo Zarcadeuk, anh ấy đã thêm sạc USB-C với chỉ báo mức năng lượng pin, giắc cắm âm thanh và tùy chọn tắt an toàn cho công tắc nguồn. Vỏ được sử dụng để chứa phần cứng sẽ yêu cầu một chút sửa đổi để mọi thứ vừa vặn, vì vậy việc bạn muốn sử dụng phần cứng gốc hay vỏ sao chép hay không là tùy thuộc vào bạn.
Hình ảnh 1 của 5
(Nguồn: Zarcadeuk)
(Nguồn: Zarcadeuk)
(Nguồn: Zarcadeuk)
(Nguồn: Zarcadeuk)
(Nguồn: Zarcadeuk)
Bộ sản phẩm đi kèm với một vài thành phần cần được hàn vào vị trí. Điều này bao gồm màn hình LCD 2,8 inch, các nút vai, giắc cắm tai nghe, bánh xe âm lượng cũng như các điểm tiếp xúc nút. Nếu bạn không ngại trả thêm một chút, Zarcadeuk cung cấp một mô-đun hàn sẵn với tất cả các bộ phận này được hàn sẵn cho bạn.
Bộ công cụ này không được thiết kế để chơi các trò chơi Game Boy Advance gốc, mà phục vụ như một nền tảng mô phỏng—do đó có tên là Mame Boy Advance SP. Phần mềm bạn chọn để chạy trên Raspberry Pi sẽ quyết định trải nghiệm. Các nút trên PCB sẽ cung cấp đầu vào mà bạn cần để vận hành hệ thống mà bạn chọn. Nó chỉ hoạt động tốt với các hệ điều hành chơi game cổ điển chuyên dụng như Retro Pie hoặc Lakka.
Zarcadeuk xác nhận Mame Boy Advance SP mới đã có sẵn để đặt hàng trước trên trang web Zega Mame Gear của anh ấy. Bộ cơ bản có giá khởi điểm là $33 USD (£34) và ước tính sẽ bắt đầu giao hàng vào ngày 10 tháng 6 vào mùa hè này. Nếu bạn là người say mê các sáng tạo vi điện tử thú vị, hãy xem danh sách các dự án Raspberry Pi của chúng tôi để xem cộng đồng nhà sản xuất đã làm gì khác gần đây.
Rất nhiều điều đang xảy ra trên thế giới xung quanh chúng ta mà chúng ta không thể dễ dàng nhìn thấy, một số trong số đó là do con người tạo ra. Dự án này, được tạo bởi một nhà sản xuất thuộc OkuboHeavyIndustries trên reddit, đã tạo ra một cách để khai thác bí ẩn đó bằng cách sử dụng bảng QtPy. Dự án thông minh này cho phép bạn xem vệ tinh nào đang quay quanh bạn trong thời gian thực. Bạn có thể sao chép dự án này bằng cách sử dụng quả mâm xôi phiên bản QtPy RP2040, nhưng OkuboHeavyIndustries sử dụng mô-đun QtPy gốc.
Một vài thành phần bổ sung là cần thiết để hoàn thành dự án. Nó có một vài màn hình để xuất dữ liệu liên quan đến vị trí của bạn và các chi tiết vệ tinh trên cao. Thứ hai, một mô-đun GPS là cần thiết để lấy vị trí hiện tại của bạn. Sau khi biết bạn đang ở đâu, nó sẽ sử dụng thông tin này để xác định vệ tinh nào hiện đang lướt qua bạn mà không nhìn thấy trên bầu trời.
Màn hình đầu tiên cung cấp thông tin chi tiết về vệ tinh đang đi qua. Màn hình thứ hai cung cấp thêm một chút thông tin. Nó không chỉ vẽ vị trí hiện tại của bạn trên bản đồ thế giới mà còn ước tính quỹ đạo của vệ tinh để bạn có thể biết nó đã ở đâu và đang đi đâu.
OkuboHeavyIndustries đã đủ tử tế để chia sẻ bảng phân tích chi tiết về phần cứng bạn cần để thực hiện dự án tại nhà. Như đã đề cập ở trên, nó được hỗ trợ bởi mô-đun QtPy được kết nối với hai màn hình. Trong trường hợp này, OkuboHeavyIndustries đang sử dụng hai màn hình SSD SSD1306. Mô-đun GPS BN-280 được sử dụng để lấy vị trí hiện tại của bạn.
Máy dò vệ tinh giống như một công cụ ước tính vệ tinh. Nó sử dụng vị trí của bạn để kiểm tra danh sách các vệ tinh có tổng số hàng nghìn—chính xác là hơn 7.500. QtPy ước tính vị trí hiện tại của nó và kiểm tra nó với vị trí hiện tại của bạn. Nếu vệ tinh được xác định là nằm trên đường chân trời của vị trí của bạn hơn 70°, vệ tinh sẽ cảnh báo bạn về sự hiện diện của vệ tinh và chia sẻ thông tin chi tiết về vệ tinh đó trên màn hình.
Kiểm tra chủ đề dự án ban đầu được chia sẻ trên reddit để xem dự án này đang hoạt động. OkuboHeavyIndustries cũng đủ tử tế để chia sẻ mã được sử dụng trong dự án tại GitHub. Nếu bạn tham gia vào các dự án vi điện tử, hãy xem danh sách tốt nhất của chúng tôi Dự án Raspberry Pi để xem thêm những sáng tạo tuyệt vời từ cộng đồng nhà sản xuất.
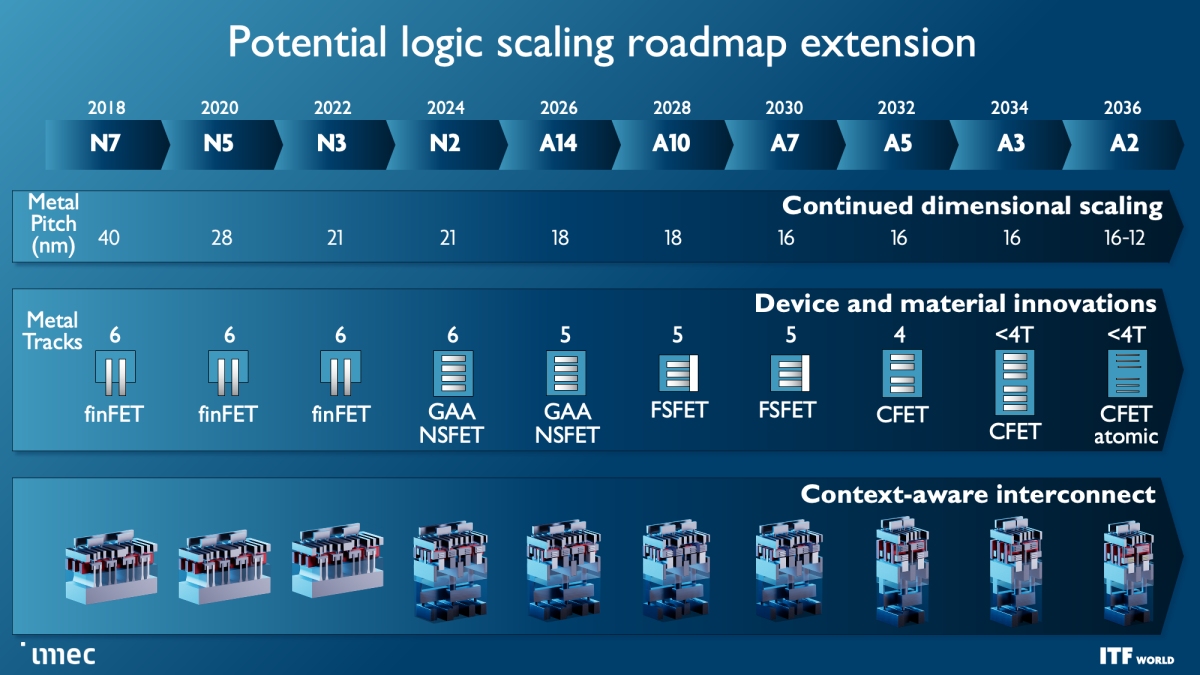
Imec, công ty nghiên cứu chất bán dẫn tiên tiến nhất thế giới, gần đây đã chia sẻ lộ trình bán dẫn và silicon dưới 1nm của mình tại sự kiện ITF World ở Antwerp, Bỉ. Lộ trình cho chúng ta ý tưởng về các mốc thời gian cho đến năm 2036 đối với các nút quy trình và kiến trúc bóng bán dẫn chính tiếp theo mà công ty sẽ nghiên cứu và phát triển trong phòng thí nghiệm của mình với sự hợp tác của những gã khổng lồ trong ngành, chẳng hạn như TSMC, Intel, Nvidia, AMD, Samsung và ASML, trong số nhiều người khác. Công ty cũng vạch ra một sự chuyển đổi sang cái mà họ gọi là CMOS 2.0, điều này sẽ liên quan đến việc chia nhỏ các đơn vị chức năng của chip, như bộ đệm L1 và L2, thành các thiết kế 3D tiên tiến hơn so với các phương pháp dựa trên chiplet ngày nay.
Xin nhắc lại, mười Angstrom bằng 1nm, vì vậy, lộ trình của Imec bao gồm các nút quy trình phụ ‘1nm’. Lộ trình phác thảo rằng các bóng bán dẫn FinFET tiêu chuẩn sẽ tồn tại cho đến 3nm nhưng sau đó sẽ chuyển sang các thiết kế tấm nano Gate All Around (GAA) mới sẽ được đưa vào sản xuất số lượng lớn vào năm 2024. Imec lập biểu đồ cho quá trình chuyển đổi các thiết kế tấm ở 2nm và A7 (0,7nm) , tiếp theo là các thiết kế đột phá như CFET và kênh nguyên tử ở A5 và A2.
(Nguồn: imec)
Việc chuyển sang các nút nhỏ hơn này đang trở nên đắt đỏ hơn theo thời gian và cách tiếp cận tiêu chuẩn để xây dựng các chip nguyên khối với một khuôn lớn duy nhất đã nhường chỗ cho các chiplet. Các thiết kế dựa trên chiplet chia các chức năng khác nhau của chip thành các khuôn riêng biệt được kết nối với nhau, do đó cho phép chip hoạt động như một đơn vị gắn kết — mặc dù có sự đánh đổi.
Tầm nhìn của Imec về mô hình CMOS 2.0 bao gồm việc chia nhỏ các chip thành nhiều phần nhỏ hơn, với bộ nhớ đệm và bộ nhớ được chia thành các đơn vị riêng với các bóng bán dẫn khác nhau, sau đó xếp chồng lên nhau theo cách sắp xếp 3D trên các chức năng khác của chip. Phương pháp này cũng sẽ dựa nhiều vào các mạng phân phối điện mặt sau (BPDN) định tuyến tất cả điện năng qua mặt sau của bóng bán dẫn.
Chúng ta hãy xem xét kỹ hơn về lộ trình imec và phương pháp mới của CMOS 2.0.
Hình ảnh 1 của 4
(Nguồn: imec)
(Nguồn: imec)
(Nguồn: imec)
(Nguồn: imec)
Như bạn có thể thấy trong album ở trên, ngành công nghiệp phải đối mặt với những thách thức dường như không thể vượt qua khi các nút phát triển, tuy nhiên nhu cầu về sức mạnh tính toán nhiều hơn, đặc biệt là cho máy học và AI, đã tăng theo cấp số nhân. Nhu cầu đó không dễ đáp ứng; chi phí đã tăng vọt trong khi mức tiêu thụ điện năng tăng đều đặn với các chip cao cấp — việc mở rộng quy mô công suất vẫn là một thách thức do điện áp hoạt động của CMOS đã kiên quyết không giảm xuống dưới 0,7 volt và nhu cầu tiếp tục mở rộng quy mô lên các chip lớn hơn sẽ đặt ra những thách thức về điện năng và khả năng làm mát. giải pháp hoàn toàn mới để phá vỡ.
Và trong khi số lượng bóng bán dẫn tiếp tục tăng gấp đôi trên con đường Định luật Moore có thể dự đoán được, thì các vấn đề cơ bản khác cũng ngày càng trở nên khó giải quyết với mỗi thế hệ chip mới, chẳng hạn như những hạn chế về băng thông kết nối đã làm chậm nghiêm trọng khả năng tính toán của CPU và GPU hiện đại, do đó cản trở hiệu suất và hạn chế hiệu quả của các bóng bán dẫn bổ sung đó.
Lộ trình nút quy trình và bóng bán dẫn imec
Hình ảnh 1 của 6
(Nguồn: imec)
(Nguồn: imec)
(Nguồn: imec)
(Nguồn: imec)
(Nguồn: imec)
(Nguồn: imec)
Tuy nhiên, các bóng bán dẫn nhanh hơn và dày đặc hơn là ưu tiên hàng đầu và làn sóng đầu tiên của các bóng bán dẫn đó sẽ đi kèm với các thiết bị Gate All Around (GAA)/Nanosheet ra mắt vào năm 2024 với nút 2nm, thay thế các FinFET ba cổng cung cấp năng lượng hàng đầu hiện nay. -chip cạnh. Các bóng bán dẫn GAA giúp cải thiện hiệu suất và mật độ bóng bán dẫn, chẳng hạn như chuyển đổi bóng bán dẫn nhanh hơn trong khi sử dụng cùng một dòng truyền động như nhiều lá tản nhiệt. Rò rỉ cũng giảm đáng kể do các kênh được bao quanh hoàn toàn bởi một cổng và việc điều chỉnh độ dày của kênh có thể tối ưu hóa mức tiêu thụ điện năng hoặc hiệu suất.
Chúng tôi đã thấy một số nhà sản xuất chip sử dụng các biến thể khác nhau của công nghệ bóng bán dẫn này. TSMC dẫn đầu ngành dự kiến ra mắt nút N2 với GAA vào năm 2025, vì vậy đây sẽ là nút cuối cùng áp dụng loại bóng bán dẫn mới. RibbonFET bốn tấm của Intel với nút xử lý ‘Intel 20A’ có bốn tấm nano xếp chồng lên nhau, mỗi tấm được bao quanh hoàn toàn bởi một cổng và sẽ ra mắt vào năm 2024. Samsung là công ty đầu tiên sản xuất GAA để vận chuyển sản phẩm, nhưng đường ống SF3E khối lượng thấp- nút sạch hơn sẽ không thấy sản xuất hàng loạt. Thay vào đó, công ty sẽ ra mắt nút tiên tiến để sản xuất số lượng lớn vào năm 2024.
Xin nhắc lại, mười Angstrom (A) bằng một 1nm. Điều đó có nghĩa là A14 là 1,4nm, A10 là 1nm và chúng ta sẽ chuyển sang kỷ nguyên dưới 1nm trong khung thời gian năm 2030 với A7. Tuy nhiên, hãy nhớ rằng các số liệu này thường không khớp với kích thước vật lý thực tế trên chip.
Imec hy vọng bóng bán dẫn forksheet sẽ bắt đầu ở 1nm (A10) và kéo dài qua nút A7 (0,7nm). Như bạn có thể thấy trong trang trình bày thứ hai, thiết kế này xếp chồng NMOS và PMOS một cách riêng biệt nhưng vẫn phân vùng chúng bằng hàng rào điện môi, cho phép đạt được hiệu suất cao hơn và/hoặc mật độ tốt hơn.
Các bóng bán dẫn FET (CFE) bổ sung sẽ thu nhỏ dấu chân hơn nữa khi chúng lần đầu tiên xuất hiện cùng với nút 1nm (A10) vào năm 2028, cho phép các thư viện tế bào tiêu chuẩn dày đặc hơn. Cuối cùng, chúng ta sẽ thấy các phiên bản CFET với các kênh nguyên tử, cải thiện hơn nữa hiệu suất và khả năng mở rộng. Các bóng bán dẫn CFET, mà bạn có thể đọc thêm tại đây, xếp chồng các thiết bị N- và PMOS lên nhau để cho phép mật độ cao hơn. CFET sẽ đánh dấu điểm kết thúc quy mô cho các thiết bị nanosheet và kết thúc lộ trình hiển thị.
Tuy nhiên, các kỹ thuật quan trọng khác sẽ cần thiết để phá vỡ các rào cản mở rộng hiệu suất, công suất và mật độ, mà imec hình dung sẽ yêu cầu mô hình CMOS 2.0 mới và đồng tối ưu hóa công nghệ hệ thống (SCTO).
STCO và Cung cấp năng lượng mặt sau
Hình ảnh 1 của 11
(Nguồn: imec)
(Nguồn: imec)
(Nguồn: imec)
(Nguồn: imec)
(Nguồn: imec)
(Nguồn: imec)
(Nguồn: imec)
(Nguồn: imec)
(Nguồn: imec)
(Nguồn: imec)
(Nguồn: imec)
Ở cấp độ cao nhất, đồng tối ưu hóa công nghệ hệ thống (STCO) yêu cầu xem xét lại quy trình thiết kế bằng cách mô hình hóa các nhu cầu của hệ thống và các ứng dụng đích, sau đó sử dụng kiến thức đó để đưa ra các quyết định thiết kế nhằm tạo ra chip. Phương pháp thiết kế này thường dẫn đến việc ‘phân rã’ các đơn vị chức năng thường được tìm thấy như một phần của bộ xử lý nguyên khối, như phân phối điện, I/O và bộ đệm, đồng thời chia chúng thành các đơn vị riêng biệt để tối ưu hóa từng đơn vị cho các đặc tính hiệu suất được yêu cầu bằng cách sử dụng khác nhau các loại bóng bán dẫn, sau đó cũng cải thiện chi phí.
Một trong những mục tiêu của việc phân tách hoàn toàn thiết kế chip tiêu chuẩn là tách bộ nhớ đệm/bộ nhớ thành lớp riêng biệt của thiết kế xếp chồng 3D (thêm về điều này bên dưới), nhưng điều này đòi hỏi phải giảm độ phức tạp ở đầu ngăn xếp chip. Cải tiến các quy trình Back End of Line (BEOL), tập trung vào việc kết nối các bóng bán dẫn với nhau và cho phép cả giao tiếp (tín hiệu) và phân phối điện, là chìa khóa cho nỗ lực này.
Không giống như các thiết kế ngày nay cung cấp năng lượng từ đỉnh chip xuống bóng bán dẫn, mạng phân phối điện mặt sau (BPDN) định tuyến tất cả điện năng trực tiếp đến mặt sau của bóng bán dẫn bằng TSV, do đó tách nguồn điện khỏi các kết nối truyền dữ liệu vẫn còn trong chúng. vị trí bình thường ở phía bên kia. Việc tách riêng mạch nguồn và các kết nối mang dữ liệu giúp cải thiện các đặc tính giảm điện áp, cho phép chuyển đổi bóng bán dẫn nhanh hơn đồng thời cho phép định tuyến tín hiệu dày đặc hơn trên đỉnh chip. Tính toàn vẹn của tín hiệu cũng có lợi vì định tuyến được đơn giản hóa cho phép đi dây nhanh hơn với điện trở và điện dung giảm.
Việc di chuyển mạng cung cấp năng lượng xuống dưới cùng của chip cho phép liên kết giữa tấm bán dẫn với tấm bán dẫn dễ dàng hơn ở phần trên của khuôn, do đó mở ra khả năng xếp chồng logic trên bộ nhớ. Imec thậm chí còn hình dung có thể chuyển các chức năng khác sang mặt sau của tấm wafer, như kết nối toàn cầu hoặc tín hiệu đồng hồ.
Intel đã công bố phiên bản riêng của kỹ thuật BPDN, được đặt tên là PowerVIA, sẽ ra mắt vào năm 2024 với nút 20A. Intel sẽ tiết lộ thêm chi tiết về công nghệ này tại sự kiện VLSI sắp tới. Trong khi đó, TSMC cũng đã thông báo rằng họ sẽ đưa BPDN vào nút N2P sẽ được sản xuất với số lượng lớn vào năm 2026, vì vậy hãng sẽ tụt hậu so với Intel trong một thời gian khá dài với công nghệ này. Samsung cũng được đồn đại sẽ áp dụng công nghệ này với nút 2nm của mình.
CMOS 2.0: Con đường dẫn đến chip 3D đích thực
Hình ảnh 1 của 16
(Nguồn: imec)
(Nguồn: imec)
(Nguồn: imec)
(Nguồn: imec)
(Nguồn: imec)
(Nguồn: imec)
(Nguồn: imec)
(Nguồn: imec)
(Nguồn: imec)
(Nguồn: imec)
(Nguồn: imec)
(Nguồn: imec)
(Nguồn: imec)
(Nguồn: imec)
(Nguồn: imec)
(Nguồn: imec)
CMOS 2.0 là đỉnh cao tầm nhìn của imec đối với các thiết kế chip trong tương lai, bao gồm các thiết kế chip 3D hoàn chỉnh. Chúng ta đã thấy bộ nhớ xếp chồng với 3D V-Cache thế hệ thứ hai của AMD xếp bộ nhớ L3 lên trên bộ xử lý để tăng dung lượng bộ nhớ, nhưng imec hình dung toàn bộ hệ thống phân cấp bộ đệm được chứa trong các lớp riêng của nó, với các bộ đệm L1, L2 và L3 được xếp chồng lên nhau theo chiều dọc trên các khuôn của chính chúng phía trên các bóng bán dẫn bao gồm các lõi xử lý.
Mỗi cấp độ bộ đệm sẽ được tạo bằng các bóng bán dẫn phù hợp nhất cho tác vụ, nghĩa là các nút cũ hơn dành cho SRAM, điều này đang trở nên quan trọng hơn khi quy mô SRAM đã bắt đầu chậm lại rất nhiều. Việc giảm quy mô của SRAM đã dẫn đến việc bộ nhớ đệm tiêu thụ phần trăm khuôn cao hơn, do đó dẫn đến chi phí trên mỗi MB tăng lên và không khuyến khích các nhà sản xuất chip sử dụng bộ nhớ đệm lớn hơn. Do đó, việc giảm chi phí liên quan đến việc chuyển sang các nút ít mật độ hơn cho bộ nhớ đệm với tính năng xếp chồng 3D cũng có thể dẫn đến các bộ nhớ đệm lớn hơn nhiều so với những gì chúng ta đã thấy trước đây. Nếu được triển khai đúng cách, tính năng xếp chồng 3D cũng có thể giúp giảm bớt lo ngại về độ trễ liên quan đến bộ nhớ đệm lớn hơn.
Các kỹ thuật CMOS 2.0 này sẽ tận dụng công nghệ xếp chồng 3D, chẳng hạn như liên kết lai giữa tấm bán dẫn với tấm bán dẫn lai, để tạo thành một kết nối 3D hoàn toàn trực tiếp mà bạn có thể đọc thêm tại đây.
Như bạn có thể thấy trong album trên, Imec cũng có một lộ trình 3D-SOC vạch ra việc tiếp tục thu hẹp các kết nối sẽ liên kết các thiết kế 3D với nhau, do đó cho phép kết nối nhanh hơn và dày đặc hơn trong tương lai. Những tiến bộ này sẽ được thực hiện bằng cách sử dụng các loại kết nối và phương pháp xử lý mới hơn trong những năm tới.
Giới thiệu imec
Bạn có thể không quen thuộc với Interuniversity Microelectronics Center (imec), nhưng nó được xếp hạng trong số những công ty quan trọng nhất trên thế giới. Hãy nghĩ về imec như một loại silicon của Thụy Sĩ. Imec đóng vai trò là nền tảng thầm lặng của ngành, mang các đối thủ cạnh tranh khốc liệt như AMD, Intel, Nvidia, TSMC và Samsung cùng với các nhà sản xuất công cụ chip như ASML và Vật liệu ứng dụng, chưa kể các công ty thiết kế phần mềm bán dẫn quan trọng (EDA) như Cadence và Synopsys, trong số những thứ khác, trong một môi trường không cạnh tranh.
Sự hợp tác này cho phép các công ty làm việc cùng nhau để xác định lộ trình của thế hệ công cụ và phần mềm tiếp theo mà họ sẽ sử dụng để thiết kế và sản xuất các con chip cung cấp năng lượng cho thế giới. Một cách tiếp cận được tiêu chuẩn hóa là tối quan trọng khi đối mặt với chi phí ngày càng tăng và độ phức tạp của quy trình sản xuất chip. Các nhà sản xuất chip hàng đầu sử dụng nhiều thiết bị giống nhau có nguồn gốc từ một số nhà sản xuất công cụ quan trọng, vì vậy cần phải có một số mức độ tiêu chuẩn hóa và việc phá vỡ các định luật vật lý đòi hỏi nỗ lực R&D có thể bắt đầu trước cả thập kỷ, vì vậy, lộ trình của imec mang lại cho chúng tôi một phạm vi rộng quan điểm về những tiến bộ sắp tới trong ngành công nghiệp bán dẫn.
GitLab đã công bố vào thứ Hai nền tảng GitLab 16 mới, một giải pháp DevSecOps dựa trên AI được nâng cấp và toàn diện. GitLab 16 bao gồm hơn 55 cải tiến và tính năng mới. Các bản nâng cấp dự kiến sẽ sớm ra mắt. GitLab 16 có sẵn cho khách hàng trên toàn cầu và có gói Miễn phí, Cao cấp và Cuối cùng.
Chuyển đến:
Có gì mới trong GitLab 16?
Trong nền tảng AI-DevSecOps của GitLab 16, các công nghệ mới đáng chú ý nhất bao gồm Bảng điều khiển luồng giá trị, Quản lý chính sách tập trung, GitLab chuyên dụng và các công cụ AI bao gồm Tái cấu trúc mã này và Giải quyết lỗ hổng này.
Bảng điều khiển luồng giá trị
Với Quản lý luồng giá trị mới, người dùng có thể trực quan hóa luồng công việc DevSecOps từ đầu đến cuối, quản lý quy trình phát triển phần mềm và hiểu rõ hơn về cách chuyển đổi kỹ thuật số và đầu tư công nghệ đang mang lại giá trị và thúc đẩy kết quả kinh doanh (Hình A).
Hình A
Bảng điều khiển luồng giá trị. Hình ảnh: GitLab
Trang tổng quan cho phép người dùng có chế độ xem toàn doanh nghiệp về số liệu DevSecOps, thời gian chu kỳ và các số liệu quan trọng khác như lỗ hổng nghiêm trọng và tần suất triển khai. GitLab cung cấp báo cáo khả thi về các quy trình công việc và số liệu phổ biến mà không cần cài đặt hay định cấu hình. Những người muốn tìm hiểu sâu hơn có thể tùy chỉnh theo dõi số liệu bằng cách sử dụng kho dữ liệu GitLab.
David DeSanto, giám đốc sản phẩm của GitLab, giải thích: “GitLab giúp các tổ chức xây dựng phần mềm tốt hơn, an toàn hơn, nhanh hơn, tăng hiệu quả hoạt động và giảm rủi ro về bảo mật và tuân thủ. “GitLab 16 nhằm mục đích làm cho những kết quả này có thể đạt được đối với các tổ chức thuộc mọi quy mô, từ các công ty mới thành lập đến các doanh nghiệp lớn và mở rộng quy mô cùng với họ khi họ phát triển.”
Bảng điều khiển luồng giá trị có thể:
So sánh các số liệu trong các khoảng thời gian.
Xác định xu hướng giảm sớm.
Tiết lộ các vấn đề phơi nhiễm bảo mật.
Đi sâu vào các dự án hoặc số liệu riêng lẻ để hành động.
Cung cấp khả năng hiển thị và khả năng truy cập dữ liệu cho tất cả các bên liên quan từ giám đốc điều hành đến những người đóng góp.
Xác định lãng phí và không hiệu quả để tối ưu hóa quy trình làm việc.
Xem và quản lý các quy trình từ đầu đến cuối.
Theo dõi dòng chảy và tăng tốc.
Sử dụng số liệu DORA4 để đánh giá mức độ trưởng thành của DevSecOps.
Theo dõi thời gian thực hiện thay đổi và tần suất triển khai để đo lường hiệu quả của quy trình DevSecOps.
An ninh chuỗi cung ứng
Các công cụ hiện có của GitLab giúp các nhóm cân bằng tốc độ và bảo mật bằng cách tự động phân phối phần mềm và đảm bảo chuỗi cung ứng phần mềm đầu cuối của khách hàng. Với GitLab 16, các công ty sẽ được hưởng lợi từ các tính năng bảo mật mới để bắt đầu, mở rộng quy mô và bảo mật chuỗi cung ứng phần mềm của họ, cũng như có được khả năng hiển thị đầy đủ về bối cảnh mối đe dọa của họ và thiết lập các chính sách để hỗ trợ tuân thủ (Hình B).
Hình B
Bảng điều khiển lỗ hổng bảo mật chuỗi cung ứng. Hình ảnh: GitLab
Các tính năng bảo mật chuỗi cung ứng mới cho GitLab 16 bao gồm:
Tăng cường quản lý chính sách tập trung.
Các báo cáo và kiểm soát tuân thủ mở rộng.
Bảng điều khiển tuân thủ.
Chứng thực SLSA Cấp 3 mặc định.
GitLab chuyên dụng: Công nghệ tuân thủ và quy định
GitLab 16 sẽ bao gồm GitLab chuyên dụng. Tính năng này hiện đang được cung cấp hạn chế và sẽ được cung cấp rộng rãi.
GitLab Dành riêng là một giải pháp phần mềm dưới dạng dịch vụ dành cho một bên thuê, cung cấp cho các tổ chức trong các ngành được quản lý chặt chẽ các công cụ để đáp ứng các yêu cầu tuân thủ phức tạp. Lợi ích chính của nó là lưu trữ dữ liệu, cách ly và kết nối mạng riêng.
Với GitLab Dành riêng, GitLab hoàn toàn quản lý và lưu trữ từng phiên bản đối tượng thuê đơn với cách ly dữ liệu và nơi cư trú.
DeSanto cho biết: “GitLab tiếp tục phát triển nền tảng của chúng tôi và các khả năng của nó với tính bảo mật và tuân thủ, đây là chìa khóa cho các tổ chức trong các ngành công nghiệp và khu vực công được quản lý chặt chẽ.
DeSanto đưa ra ví dụ về Lockheed Martin. Nhà thầu quốc phòng Mỹ gần đây đã tiết lộ cách họ sắp xếp hợp lý quá trình phát triển và triển khai phần mềm, giảm 90% thời gian bảo trì hệ thống và tăng cường bảo mật bằng cách hợp tác với GitLab và AWS.
Quy trình công việc được hỗ trợ bởi AI
Các giải pháp GitLab bao gồm các tính năng do AI cung cấp bao gồm Đề xuất mã, Giải thích mã này, Giải thích lỗ hổng này và Dự báo luồng giá trị. GitLab 16 bổ sung các công cụ AI mới: Tái cấu trúc mã này và giải quyết lỗ hổng này. Với những công cụ này, công ty chuyển từ việc sử dụng AI để xác định các mối đe dọa, giải thích mã và dự đoán các chu kỳ tương lai của dòng giá trị sang sử dụng công nghệ AI để thực hiện các hành động và giải quyết vấn đề.
Quy trình công việc dựa trên AI của GitLab có thể:
Thúc đẩy hiệu quả và giảm thời gian chu kỳ cho mọi giai đoạn của vòng đời phát triển phần mềm.
Đảm bảo sự riêng tư.
Hỗ trợ tất cả các nhóm chuỗi cung ứng.
Tăng tốc và nâng cao hiệu quả viết mã.
Dự đoán năng suất và phát hiện sự bất thường.
Giúp khắc phục các lỗ hổng.
Luôn cập nhật tài năng bằng cách giải thích mã nguồn.
Tái cấu trúc mã.
Giải quyết các lỗ hổng tự động.
DevSecOps chuyển sang trái với sự đổi mới và AI
GitLab 16 là phản ứng trực tiếp đối với nhu cầu thị trường kêu gọi hợp nhất các công cụ DevSecOps và sử dụng AI để phát triển phần mềm tốt hơn và vận chuyển phần mềm đó nhanh hơn.
DeSanto cho biết: “Các nhóm Dev, Sec và Ops đang cảm thấy áp lực hơn khi nói đến việc quản lý chuỗi công cụ. “Nền kinh tế bị hạn chế, ngân sách bị thắt chặt và các chuyên gia DevSecOps đang được giao nhiệm vụ ‘làm nhiều hơn với chi phí ít hơn’ khi các tổ chức đặt mục tiêu cung cấp phần mềm nhanh hơn và hiệu quả hơn.”
GitLab đã khảo sát 5.000 chuyên gia DevSecOps để hiểu rõ hơn về các ưu tiên và tình trạng phát triển, bảo mật và vận hành phần mềm. Báo cáo DevSecOps toàn cầu năm 2023 Bảo mật không cần hy sinh tiết lộ rằng 74% chuyên gia bảo mật đã chuyển sang trái hoặc dự định chuyển sang bảo mật trong ba năm tới.
Chuyển sang trái là một thay đổi quan trọng trong cách phát triển phần mềm theo truyền thống, chuyển bảo mật, tuân thủ, thử nghiệm, chất lượng và đánh giá hiệu suất sang các giai đoạn đầu của quá trình phát triển phần mềm. Khảo sát của GitLab cũng chỉ ra rằng các nhà phát triển hàng đầu tin rằng có quá nhiều công cụ công nghệ. Hơn một nửa (66%) những người được khảo sát cho biết họ muốn hợp nhất chuỗi công cụ của mình.
XEM: DevSecOps: AI đang định hình lại vai trò của nhà phát triển, nhưng không phải tất cả đều thuận buồm xuôi gió (TechRepublic)
Nhưng lực lượng đột phá chính trong DevSecOps là sự đổi mới: 61% nhà phát triển cho biết họ đã sử dụng AI và máy học để kiểm tra mã, tăng từ 51% vào năm 2022. GitLab cũng nhận thấy rằng bảo mật, hiệu quả và tự động hóa là những lợi ích hàng đầu của nền tảng DevSecOps .
DeSanto cho biết: “Các khả năng tập trung vào luồng công việc và được hỗ trợ bởi AI mới của GitLab nhằm đáp ứng nhu cầu của ngành bằng cách giúp các nhà phát triển phần mềm cải thiện năng suất và tính bảo mật của mã của họ. “AI và máy học đang trở thành những thành phần quan trọng của quy trình làm việc DevSecOps.”
Trong một blog gần đây về GitLab 16, công ty đã nêu bật các tính năng dựa trên các tính năng được AI hỗ trợ: không gian làm việc phát triển từ xa, mẫu nhận xét và trình chạy GitLab SaaS mạnh mẽ hơn, cũng như các Đề xuất mã được hỗ trợ bởi AI được cải tiến.
Các lựa chọn thay thế GitLab hàng đầu
Các lựa chọn thay thế hàng đầu cho GitLab vào năm 2023 theo đánh giá của Gartner Peer Insights là Red Hat Ansible Automation Platform, Octopus Deploy, Azure Pipelines, IBM Urban Code Deploy, CloudBees và Micro Focus Release Control.
XEM: Đánh giá công cụ GitLab CI/CD (TechRepublic)
Tất cả các giải pháp phát triển phần mềm hàng đầu đều đang tích hợp các công cụ AI vào phần mềm của họ. Với các bài đánh giá xếp hạng cao, các nhà cung cấp cạnh tranh khốc liệt trên thị trường dành cho nhà phát triển phần mềm, thị trường dự kiến sẽ tạo ra doanh thu 659 tỷ USD trên toàn thế giới vào năm 2023.
Điều gì làm nên sự khác biệt của GitLab trong thị trường phát triển phần mềm?
GitLab tạo sự khác biệt với các nhà cung cấp khác bằng cách cung cấp một cách tiếp cận độc đáo cho DevSecOps. Nó phổ biến đối với các nhà phát triển vì hầu hết các công cụ họ cần đều có sẵn và được tích hợp vào nền tảng. Tích hợp, phát triển và nâng cấp liên tục là chìa khóa thành công của nó.
Ngoài ra, GitLab không ngừng nâng cấp và cải tiến nền tảng của mình. Các bản phát hành GitLab 16.1 đã được trình bày chi tiết trên trang phát hành sắp tới của công ty. GitLab vẫn có tính cạnh tranh cao, với hơn 30 triệu người dùng đã đăng ký và hơn 50% công ty trong danh sách Fortune 100 sử dụng nền tảng và công nghệ của GitLab để phát triển và vận chuyển phần mềm.
DeSanto cho biết: “Chúng tôi tin rằng giá trị biến đổi của AI đến từ việc kết hợp nó trong các chức năng công việc, không chỉ trong việc tạo mã. “Triển khai AI trong toàn bộ sản phẩm của chúng tôi giúp chúng tôi đáp ứng nhu cầu của ngành và hỗ trợ những khách hàng đang tìm cách nâng cao hiệu quả, tích hợp bảo mật và cung cấp phần mềm với tốc độ của thị trường.”
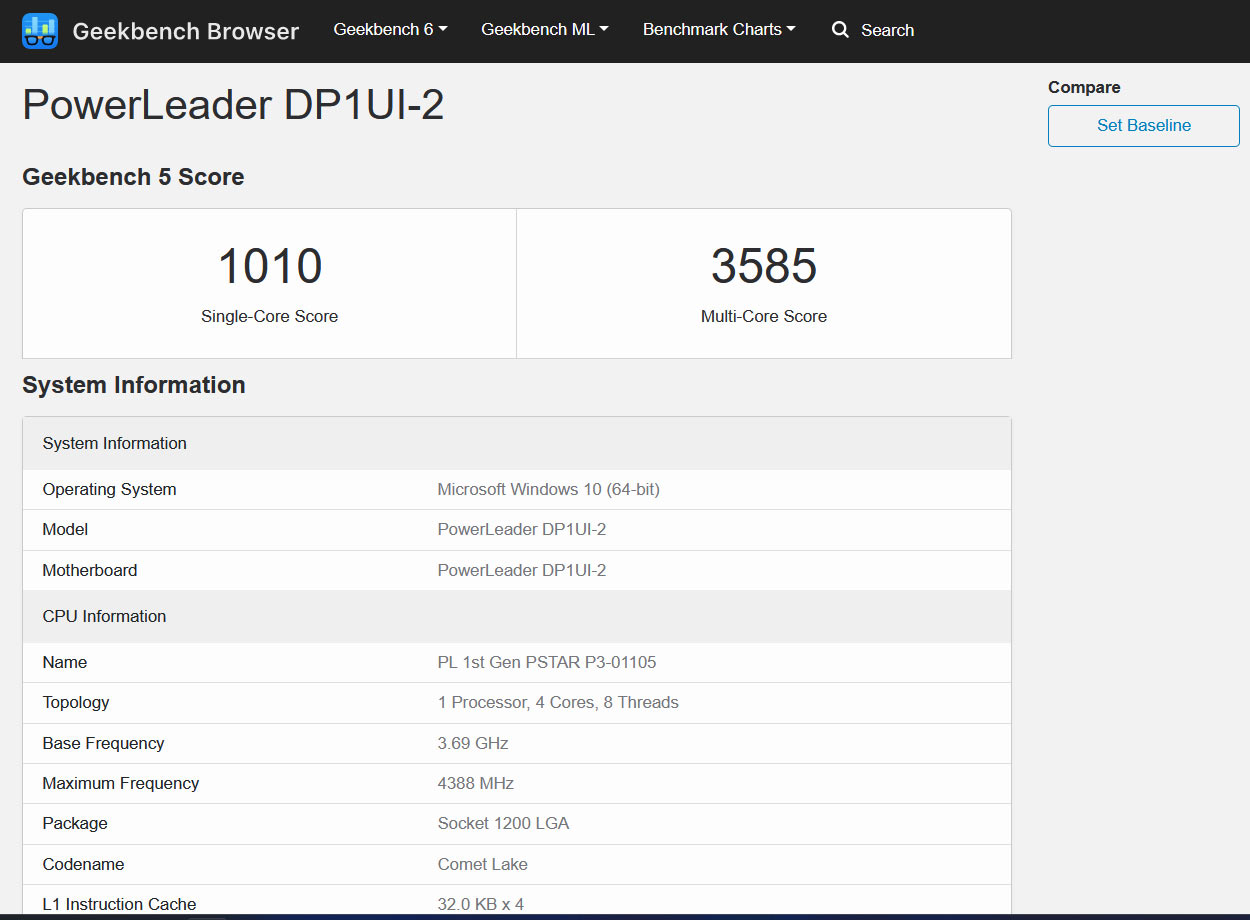
CPU Powerstar P3-01105 của Trung Quốc đã xuất hiện trong Geekbench v5 trình duyệt kết quả trực tuyến. Điều quan trọng là phần thông tin hệ thống của điểm chuẩn dường như xác nhận rằng chip 4C / 8T này chắc chắn là do Intel sản xuất, vì phần Socket 1200 LGA này có CPUID A0653 (Chính hãngIntel) và được cho là sử dụng kiến trúc Intel Comet Lake.
Đầu tháng này, chúng tôi đã báo cáo về CPU Powerstar P3-01105 thế hệ đầu tiên mới ra mắt. PowerLeader của Trung Quốc coi con chip này là một sản phẩm tự sản xuất trong nước sử dụng kiến trúc “lõi bão”, trong khi vẫn tương thích với x86. Tuy nhiên, đã có khá nhiều bằng chứng chỉ ra rằng chip ‘Trung Quốc’ là CPU Intel Core i3-10105(F) Comet Lake đã được đổi thương hiệu với 4C / 8T.
(Nguồn: ITHome)
Bằng chứng trước đây về sự tương đồng giữa Powerstar/Intel Comet Lake bao gồm:
Thiết kế tản nhiệt có vấu vật lý và các đặc tính vật lý khác
Thiết kế chất nền vật lý giống hệt nhau, theo như chúng ta có thể thấy
Định dạng in lụa trên IHS là như nhau
Tên bộ xử lý PowerLeader hơi lộn xộn với Intel: so sánh “10105” và “01105”
Cả hai đều được đánh dấu là có khả năng chạy đồng hồ cơ sở “3,70GHZ”
Mã QR ở phía trên bên phải của Powerstar P3-01105 PCB được cho là khớp với mã của Intel.
Các mới bằng chứng từ Geekbench có lẽ là quá đủ để hầu hết mọi người chắc chắn về nguồn gốc của CPU Powerstar P3-01105. Tuy nhiên, chúng ta vẫn phải giữ một số nghi ngờ, vì những kẻ chơi khăm nghịch ngợm với những thứ như báo cáo thông tin hệ thống Geekbench chỉ để cho vui.
(Nguồn: Tương lai)
PowerLeader có mục tiêu đầy tham vọng là bán được 1,5 triệu chiếc CPU Powerstar P3-01105. Chúng tôi nghĩ rằng CPU là một bộ phận ‘Chính hãng của Intel’ chỉ có thể giúp đạt được mục tiêu này, vì “lõi bão” được chào hàng khi ra mắt không có lịch sử và ngay cả những người lạc quan cũng mong đợi một số trục trặc trong một sản phẩm ‘thế hệ đầu tiên’ thực tế.
Những người đam mê PC và những người tự làm ở phương Tây giờ đây có thể nghĩ đến việc tìm nguồn cung ứng CPU Powerstar P3-01105 cho các bản dựng ngân sách. Tuy nhiên, sự ra mắt của PowerLeader cho thấy các chip này sẽ chỉ được cung cấp trong các hệ thống đầy đủ. Chúng ta sẽ phải xem xét điều đó trong những tuần / tháng tới.
Như chúng ta đã thấy bề mặt Powerstar trong Geekbench, có lẽ chúng ta có thể đợi vài tuần trước khi một số YouTuber Trung Quốc táo bạo (hoặc Bilibili-er hoặc Weibo-er) chia sẻ một số thông tin chuyên sâu hơn, các bài kiểm tra và điểm chuẩn của P3 -01105 CPU.
Theo một cách nào đó, việc PowerLeader cải tiến một thứ phức tạp và mang tính Mỹ như CPU Intel, trái ngược với thông báo gần đây rằng các sản phẩm bộ nhớ Micron đã bị cấm đối với các tổ chức có kết nối với cơ sở hạ tầng thông tin quan trọng của Trung Quốc.
Hiểu sự khác biệt chính giữa Square Payroll và OnPay, hai giải pháp trả lương phổ biến. Chúng tôi phác thảo giá cả, tính năng cũng như ưu và nhược điểm của từng loại để bạn có thể đưa ra lựa chọn phù hợp cho doanh nghiệp của mình vào năm 2023.
Square Payroll và OnPay là hai giải pháp phần mềm tính lương phổ biến được thiết kế để hợp lý hóa quy trình tính lương và nâng cao hiệu quả cho doanh nghiệp. Square Payroll được biết đến với giao diện thân thiện với người dùng và tích hợp liền mạch với các sản phẩm khác của Square, phục vụ chủ yếu cho các doanh nghiệp nhỏ. Mặt khác, OnPay cung cấp giải pháp nhân sự và bảng lương toàn diện phù hợp với nhiều loại hình doanh nghiệp, tập trung mạnh vào tính tuân thủ và tính linh hoạt.
Chuyển đến:
Square Payroll so với OnPay: Bảng so sánh
Đặc trưng
Bảng lương vuông
OnPay
xử lý bảng lương
Đúng
Đúng
Kê khai và nộp thuế
Đúng
Đúng
Nhân viên tự phục vụ
Đúng
Đúng
tính năng nhân sự
Giới hạn
Đúng
Quản lý lợi ích tích hợp
KHÔNG
Đúng
Theo dõi thời gian tích hợp
Đúng
KHÔNG
Định giá mỗi tháng
$35 phí cơ bản + $5/nhân viên
$40 phí cơ bản + $6/nhân viên
Đối tác nổi bật
Định giá Square Payroll và OnPay
Định giá Square Payroll rất đơn giản và được thiết kế để phục vụ cho các doanh nghiệp nhỏ. Nó tính phí cơ bản 35 đô la mỗi tháng và thêm 5 đô la cho mỗi nhân viên mỗi tháng. Cấu trúc giá này đơn giản và dễ hiểu, cho phép doanh nghiệp lập ngân sách và lập kế hoạch chi phí tiền lương một cách hiệu quả.
XEM: Tìm kiếm một giải pháp thay thế cho OnPay? Đây là một so sánh của các đối thủ cạnh tranh OnPay hàng đầu và các lựa chọn thay thế.
Mặt khác, OnPay có giá cao hơn một chút. Nó tính phí cơ bản 40 đô la mỗi tháng và 6 đô la cho mỗi nhân viên mỗi tháng. Cấu trúc này vẫn minh bạch và giá cả phải chăng cho nhiều doanh nghiệp. Tuy nhiên, điều cần thiết là phải đánh giá xem liệu có phải trả thêm phí cho các tính năng bổ sung như quản lý phúc lợi, công cụ nhân sự hoặc tích hợp với phần mềm của bên thứ ba hay không.
Các doanh nghiệp cũng nên để mắt đến các chi phí ẩn tiềm ẩn, chẳng hạn như phí thực hiện. Tuy nhiên, cả hai sản phẩm đều hứa hẹn sẽ bao gồm mọi thứ bạn có thể cần trong các gói này mà không có phí ẩn hoặc phí lén lút.
Để phân tích chi tiết hơn về cấu trúc giá cả và các tính năng của từng sản phẩm, hãy xem các bài đánh giá sản phẩm Square Payroll và OnPay của chúng tôi.
So sánh tính năng: Square Payroll so với OnPay
xử lý bảng lương
Cả Square Payroll và OnPay đều cung cấp khả năng xử lý bảng lương hiệu quả, đảm bảo thanh toán chính xác và kịp thời cho nhân viên. Họ cung cấp các tính năng như nhiều tùy chọn thanh toán, tính thuế tự động và gửi tiền trực tiếp. Mặc dù cả hai giải pháp đều vượt trội trong việc xử lý bảng lương, nhưng Square Payroll được công nhận nhờ giao diện thân thiện với người dùng (Hình A), làm cho nó đặc biệt phù hợp cho các doanh nghiệp nhỏ. Ngược lại, OnPay cung cấp một giải pháp toàn diện hơn có thể đáp ứng nhu cầu của các doanh nghiệp thuộc nhiều quy mô khác nhau.
Hình A
Giao diện người dùng OnPay hiển thị báo cáo bảng lương. Hình ảnh: OnPay
Kê khai và nộp thuế
Square Payroll và OnPay xử lý việc nộp thuế (Hình B) và thanh toán cho doanh nghiệp của bạn, đơn giản hóa quy trình và giúp bạn tuân thủ các quy định về thuế. Chúng tự động tính toán, khấu trừ và nộp thuế biên chế liên bang và tiểu bang, giảm nguy cơ sai sót và hình phạt. OnPay nổi bật nhờ đảm bảo nộp hồ sơ thuế, đề nghị chi trả mọi hình phạt hoặc tiền phạt phát sinh do sai sót do phần mềm của OnPay gây ra.
Hình B
Square Payroll cho phép người dùng xem các biểu mẫu thuế của họ trong nền tảng. Hình ảnh: Bảng lương Square
Nhân viên tự phục vụ
Cả Square Payroll và OnPay đều cung cấp cổng thông tin tự phục vụ cho nhân viên (Hình C), cho phép nhân viên truy cập cuống phiếu lương, cập nhật thông tin cá nhân và quản lý khoản giữ lại của họ. Các cổng này giúp giảm khối lượng công việc của nhân viên nhân sự bằng cách trao quyền cho nhân viên quản lý thông tin của chính họ, dẫn đến hồ sơ chính xác hơn và quy trình tính lương mượt mà hơn.
Hình C
Cổng thông tin tự phục vụ OnPay hiển thị sơ đồ tổ chức. Hình ảnh: OnPay
tính năng nhân sự
OnPay cung cấp nhiều tính năng nhân sự hơn so với Square Payroll. Bộ nhân sự của OnPay bao gồm giới thiệu, quản lý hiệu suất, theo dõi PTO và lưu trữ tài liệu. Mặt khác, Square Payroll cung cấp chức năng nhân sự hạn chế, chủ yếu tập trung vào xử lý bảng lương. Các doanh nghiệp yêu cầu khả năng quản lý nhân sự toàn diện có thể thấy OnPay phù hợp hơn, trong khi những doanh nghiệp đang tìm kiếm một giải pháp trả lương đơn giản có thể xem xét Square Payroll.
XEM: Khám phá thay thế tốt nhất cho Square Payroll cho năm 2023.
quản lý phúc lợi
OnPay cung cấp các tính năng quản lý phúc lợi mạnh mẽ, cho phép doanh nghiệp quản lý bảo hiểm y tế, kế hoạch hưu trí và các phúc lợi khác của nhân viên. Square Payroll không cung cấp tính năng quản lý lợi ích tích hợp, đây có thể là một nhược điểm đối với các doanh nghiệp yêu cầu chức năng này. Các công ty cần các tùy chọn quản lý lợi ích toàn diện nên xem xét OnPay, trong khi những công ty chỉ tập trung vào xử lý bảng lương có thể thấy Square Payroll là đủ.
theo dõi thời gian
Square Payroll và OnPay đều bao gồm các tính năng theo dõi thời gian, cho phép doanh nghiệp theo dõi chính xác giờ làm việc của nhân viên và đảm bảo tính toán bảng lương chính xác. Square Payroll tích hợp với hệ thống điểm bán hàng và ứng dụng theo dõi thời gian của Square, trong khi OnPay cung cấp đồng hồ thời gian tích hợp và hỗ trợ tích hợp với các công cụ theo dõi thời gian phổ biến. Tuy nhiên, OnPay không có tính năng theo dõi thời gian tích hợp. Cả hai giải pháp đều giúp cải thiện năng suất và giảm sai sót trong bảng lương bằng cách duy trì hồ sơ chấm công chính xác.
Ưu và nhược điểm của Square Payroll
Ưu điểm của Square Payroll
Giao diện thân thiện với người dùng giúp đơn giản hóa quá trình xử lý bảng lương, khiến nó đặc biệt phù hợp với các doanh nghiệp nhỏ và người dùng lần đầu.
Tích hợp liền mạch với hệ thống điểm bán hàng và các ứng dụng theo dõi thời gian của Square đảm bảo quy trình làm việc gắn kết giữa các chức năng khác nhau.
Cấu trúc giá minh bạch với phí cố định hàng tháng và chi phí cho mỗi nhân viên, cho phép doanh nghiệp dễ dàng hiểu và lập kế hoạch chi tiêu.
Nhược điểm của Square Payroll
Các tính năng nhân sự hạn chế trong dịch vụ cốt lõi có thể không đáp ứng đầy đủ cho các doanh nghiệp có yêu cầu quản lý nhân sự toàn diện hơn.
Thiếu quản lý lợi ích tích hợp có thể là một nhược điểm đối với các doanh nghiệp cần quản lý lợi ích của nhân viên như một phần của giải pháp trả lương của họ.
Ưu và nhược điểm của OnPay
Ưu điểm của OnPay
Các tính năng nhân sự và bảng lương toàn diện đáp ứng nhiều nhu cầu kinh doanh khác nhau, cung cấp giải pháp tất cả trong một để quản lý lực lượng lao động của bạn.
Khả năng quản lý lợi ích mạnh mẽ cho phép doanh nghiệp tùy chỉnh các dịch vụ của họ để thu hút và giữ chân nhân tài hàng đầu.
Đảm bảo nộp thuế cung cấp để trang trải mọi khoản phạt hoặc tiền phạt phát sinh do lỗi do phần mềm của OnPay gây ra, đảm bảo sự an tâm cho doanh nghiệp.
Nhược điểm của OnPay
Bộ tính năng và giao diện phức tạp hơn có thể yêu cầu quá trình học tập phức tạp hơn so với các giải pháp tính lương đơn giản hơn như Square Payroll.
Cấu trúc định giá, với phí cơ bản và chi phí cho mỗi nhân viên, có thể trở nên đắt đỏ hơn khi doanh nghiệp của bạn phát triển, đặc biệt khi so sánh với các mô hình định giá theo phí cố định.
phương pháp luận
Để đưa ra sự so sánh đáng tin cậy, chúng tôi đã phân tích các tính năng, giá cả, ưu và nhược điểm của Square Payroll và OnPay bằng cách xem xét phản hồi của khách hàng và thông số kỹ thuật của sản phẩm từ tài liệu chính thức.
Tổ chức của bạn nên sử dụng Square Payroll hay OnPay?
Quyết định giữa Square Payroll và OnPay tùy thuộc vào nhu cầu, ưu tiên cụ thể của tổ chức bạn và mức độ toàn diện mà bạn yêu cầu trong một giải pháp bảng lương. Square Payroll lý tưởng cho các doanh nghiệp nhỏ đang tìm kiếm sự đơn giản và tích hợp liền mạch với hệ thống điểm bán hàng của Square. OnPay phù hợp với các doanh nghiệp yêu cầu giải pháp nhân sự và bảng lương toàn diện với khả năng quản lý lợi ích mạnh mẽ.
Khi chọn phần mềm tính lương phù hợp cho tổ chức của bạn, hãy xem xét cẩn thận các yếu tố như tính toàn diện của các tính năng, khả năng tích hợp, cấu trúc giá cả và tính dễ sử dụng tổng thể.
Hoa Kỳ thông qua Cơ quan An ninh Quốc gia (NSA) và Cơ quan An ninh Cơ sở hạ tầng & An ninh mạng (CISA), Microsoft và các tổ chức khác đã phát hành một bản tin tình báo chung Tư vấn An ninh mạng (CSA) chỉ ra các hoạt động có trụ sở tại Hoa Kỳ của Volt Typhoon, một tổ chức, nhóm tội phạm mạng do nhà nước tài trợ hoạt động bên ngoài Trung Quốc. Báo cáo phác thảo các hoạt động được tiến hành trên đất Mỹ nhằm xâm nhập và xâm phạm cơ sở hạ tầng quan trọng trong một số lĩnh vực. Nó trình bày chi tiết hơn về cách các cá nhân gắn liền với nhóm này hoạt động mà không bị phát hiện trên đất Mỹ: bằng cách triển khai các kỹ thuật sống ngoài đất liền (có nghĩa là các tế bào biệt lập và tự cung tự cấp) và các kỹ thuật thao tác trên bàn phím (hoạt động hoàn toàn trực tuyến).
Theo Microsoft, nó có thể nói với tự tin vừa phải rằng chiến dịch của nhóm nhằm mục đích theo đuổi “sự phát triển của các khả năng có thể phá vỡ cơ sở hạ tầng liên lạc quan trọng giữa Hoa Kỳ và khu vực châu Á trong các cuộc khủng hoảng trong tương lai.”
Các phương thức tấn công ưa thích của Volt Typhoon, được xác định bởi các chuyên gia an ninh mạng và an ninh quốc gia. (Nguồn: Microsoft)
Các hoạt động của Bão Volt ở Hoa Kỳ bắt đầu từ ít nhất là giữa năm 2021, nhắm mục tiêu vào nhiều tổ chức trải rộng trên nhiều khu vực kinh tế. Các lĩnh vực Truyền thông, Sản xuất, Tiện ích, Giao thông vận tải, Xây dựng, Hàng hải, Chính phủ, Công nghệ thông tin và Giáo dục.
Số hóa (hành động đưa các khả năng kỹ thuật số vào các nhiệm vụ tương tự khác) là một thực tế trong cuộc sống của chúng ta, cũng như sự gia tăng phi mã của nó – hàng năm, các sản phẩm mới xuất hiện có thêm chức năng kỹ thuật số. Vì chức năng này thường xứng đáng với khoản đầu tư bổ sung (do giảm chi phí, tăng hiệu quả, tính thực tế hoặc bất kỳ số liệu nào khác mà thị trường mong muốn), cả công cụ tương tự và ngắt kết nối đều dần bị loại bỏ cho đến khi bị rơi vào quên lãng hoặc một thị trường ngách. Bạn sẽ ngạc nhiên về số lượng cơ sở hạ tầng truyền thông đã phụ thuộc vào các hệ thống kỹ thuật số.
Tất nhiên, vấn đề với các hệ thống kỹ thuật số là chúng có thể bị tấn công từ xa.
Trong một ví dụ hữu hình hơn, chúng ta hãy xem khi Microsoft giúp Ukraine gỡ bỏ phần mềm độc hại của Nga được cài đặt trong cơ sở hạ tầng xe điện của quốc gia này. Hệ thống đã bị nhiễm phần mềm độc hại kiểu Wiper – có thể xóa toàn bộ hệ thống hoặc các tệp quan trọng cần thiết khiến hệ thống điều khiển tàu không thể hoạt động. Điều này đã xảy ra trước chiến tranh. Sau cuộc xâm lược, cũng chính hệ thống xe lửa đó đã sơ tán một số người Ukraine tị nạn chiến tranh.
Vấn đề ở đây là số hóa có nghĩa là tăng cơ hội truy cập từ xa, do đó làm tăng khả năng bị tấn công (ví dụ, Nga tiêu tốn ít tài nguyên hơn bằng cách vô hiệu hóa kỹ thuật số một máy bay không người lái của Ukraine so với bắn tên lửa vào nó). Ngay cả khi cuộc sống của chúng ta trở nên hiệu quả hơn, công nghệ và kết nối với nhau hơn, thì ngày càng có nhiều khía cạnh trở nên dễ bị tổn thương trước loại tấn công ít tốn kém nhất và hiệu quả nhất: tấn công mạng.
Bên cạnh mong muốn tăng cường khả năng cách ly và hiệu quả quân sự trong trường hợp xung đột với Mỹ, một phần lý do nhắm mục tiêu vào liên lạc giữa Mỹ và châu Á được gọi là Đài Loan. Chúng ta đã thấy đủ bằng chứng về cuộc chiến giằng co giữa Mỹ và Trung Quốc để giành lấy viên ngọc quý công nghệ là Công ty TNHH Sản xuất Chất bán dẫn Đài Loan (TSMC). Đôi khi, trở thành “đối tượng” mong muốn nhất trong phòng đơn giản không phải là nơi tốt nhất.
Microsoft đã dần dần mở rộng khả năng kinh doanh của nền tảng Azure của mình, thêm các dịch vụ và giao diện lập trình ứng dụng có thể được sử dụng để cung cấp một tập hợp các quy trình làm việc dựa trên thông báo. Phần lớn sự phát triển này được xây dựng trên xương sống Bus dịch vụ của nó và công cụ được sử dụng để chạy cả Chức năng Azure và Dịch vụ ứng dụng Azure.
NHÌN THẤY: Tìm hiểu sâu về Microsoft Azure trực tuyến với gói đào tạo này từ Học viện TechRepublic.
Việc xây dựng kiến trúc dựa trên thông báo, hướng sự kiện trên Azure rất có ý nghĩa. Đó là một cách hiệu quả và di động để xây dựng các ứng dụng phân tán có thể mở rộng và mở rộng khi cần thiết.
Một bộ API đang phát triển là Dịch vụ liên lạc của Azure, kết nối điện toán phân tán và liên lạc bằng giọng nói, liên kết mã với mạng điện thoại công cộng và các dịch vụ liên lạc khác, như Teams. Đây là một công cụ mạnh mẽ, hỗ trợ các cuộc gọi thoại và video — cả qua internet và qua mạng điện thoại — cũng như nhắn tin qua trò chuyện, SMS và email.
Chuyển đến:
Tự động hóa dịch vụ truyền thông Azure
API Dịch vụ Giao tiếp Azure giúp dễ dàng kết hợp các công nghệ này vào mã của bạn, giúp ứng dụng có quyền truy cập trực tiếp vào khách hàng và người dùng của bạn. Điều có lẽ thú vị nhất về các công cụ này là chúng cho phép bạn xây dựng các ứng dụng trung tâm cuộc gọi tùy chỉnh của riêng mình, thêm thông tin liên lạc đa kênh vào các công cụ bán hàng và dịch vụ khách hàng hoặc như một phần của nền tảng hỗ trợ.
Mọi thứ trở nên thú vị khi bạn thêm hỗ trợ cho tự động hóa cuộc gọi, làm cho giọng nói trở thành một phần trực tiếp trong quy trình làm việc của bạn. Thay vì tích hợp các ứng dụng của bạn vào một trung tâm cuộc gọi kỹ thuật số, bạn có thể xây dựng một công cụ chuyên dụng để định tuyến và chỉ định các cuộc gọi điện thoại và web một cách thích hợp.
Với công cụ chuyên dụng này, bạn không bị giới hạn trong việc định tuyến trước cuộc gọi; mã của bạn có thể xử lý các cuộc gọi di chuyển từ điểm cuối này sang điểm cuối khác — ví dụ: khi báo cáo vấn đề hỗ trợ khách hàng. Ngoài ra còn có hỗ trợ cho các ứng dụng nhấp để gọi, thông qua web hoặc thông qua ứng dụng, cho phép kết nối video và thoại nhanh chóng từ ứng dụng người dùng đến bàn hỗ trợ.
Ngoài ra, việc phát triển mã cho các API tự động hóa khá đơn giản. Cũng như các API REST, bạn có thể sử dụng các thư viện C# hoặc Java để thêm chức năng cho các ứng dụng mới và ứng dụng hiện có.
NHÌN THẤY: Phát triển các kỹ năng mã hóa có tính thị trường cao với gói đào tạo này từ Học viện TechRepublic.
Chúng được tích hợp với cơ sở hạ tầng sự kiện của Azure, cho phép bạn xây dựng logic kinh doanh xung quanh một cuộc gọi. Điều này cho phép bạn xây dựng công cụ để quản lý và phân loại hàng đợi cuộc gọi, vì vậy nếu cuộc gọi từ một khách hàng có giá trị được chuyển vào hàng đợi, cuộc gọi đó có thể được ưu tiên hoặc chuyển đến một nhà điều hành chuyên gia.
Thêm tự động hóa vào mã của bạn
SDK C# và Java có lẽ là những cách có khả năng nhất để xây dựng quy trình giao tiếp doanh nghiệp. Cả hai đều cung cấp các tính năng giống nhau, từ thiết lập cuộc gọi đến làm việc với các cuộc gọi hiện có và quản lý ghi âm cuộc gọi.
Có một lưu ý quan trọng: Sau khi cuộc gọi đã được trả lời, bạn chỉ có thể di chuyển cuộc gọi đó giữa các điểm cuối của Dịch vụ Truyền thông Azure, vì Microsoft vẫn chưa thêm khả năng chuyển hướng cuộc gọi đến các số điện thoại khác.
Các cuộc gọi được quản lý bằng API không đồng bộ, vì vậy bạn có thể kích hoạt thông báo chào mừng và đưa cuộc gọi vào hàng đợi cho tổng đài viên cùng một lúc. Mã của bạn nằm giữa người gọi và dịch vụ thoại mà họ đang sử dụng, chỉ phản hồi khi có sự kiện mới.
Sử dụng các phương pháp không đồng bộ có nghĩa là bạn không buộc tài nguyên chờ phản hồi, đảm bảo người dùng nhận được thời gian phản hồi tốt nhất trong khi vẫn giữ chi phí tính toán ở mức tối thiểu. Bạn thậm chí có thể sử dụng phương pháp này để chuyển cuộc gọi đến đến nhiều điểm cuối, do đó, bất kỳ nhân viên chờ đợi nào cũng có thể nhận cuộc gọi đó. Ngoài ra, các cuộc gọi có thể được chuyển hướng nếu không được trả lời đủ thời gian mà người gọi không biết cuộc gọi đã được chuyển.
Khi một hành động đã hoàn thành, nó sẽ tạo ra một sự kiện mà mã của bạn cần xử lý. Các sự kiện được phân phối bằng cách sử dụng Lưới sự kiện của Azure hoặc qua Webhooks, vì vậy bạn có thể sử dụng các thư viện và kỹ thuật tiêu chuẩn để làm việc với chúng.
Thông báo cuộc gọi đến được gửi theo lưới Sự kiện, vì vậy, bạn có thể sử dụng các công cụ như Hàm Azure để phản hồi cuộc gọi và kích hoạt quy trình làm việc. Khi một cuộc gọi đã được thiết lập, bất kỳ sự kiện nào khác sẽ được phân phối bởi Webhook, nghĩa là bạn sẽ cần theo dõi ngữ cảnh của một cuộc gọi trong mã của mình. Các sự kiện gọi lại đủ đơn giản để sử dụng, với các công cụ được tích hợp trong .NET và Java.
Xây dựng trung tâm cuộc gọi tùy chỉnh của riêng bạn
Bạn sẽ thấy dịch vụ này hỗ trợ hầu hết các tính năng mà bạn mong muốn tìm thấy trong một tổng đài điện thoại hoặc trung tâm cuộc gọi, đảm bảo sự quen thuộc của người dùng và khả năng tích hợp dịch vụ này với cả quy trình công việc và công cụ hiện có. Các ứng dụng mới giờ đây có thể tận dụng các thành phần giao diện người dùng của Dịch vụ Truyền thông Azure được phát hành gần đây, giúp đơn giản hóa việc tích hợp lệnh gọi vào mã của bạn và vào các dịch vụ như Teams.
Tự động hóa luồng cuộc gọi vào và ra khỏi ứng dụng của bạn có thể giảm tải đáng kể cho nhân viên của bạn. Ví dụ: có các công cụ để giải mã âm đa tần kép, cho phép bạn xây dựng dịch vụ phản hồi bằng giọng nói tương tác tùy chỉnh.
Có lẽ bạn có thể sử dụng các công cụ ghi âm để nhận tin nhắn thoại, sau đó chuyển bản ghi âm sang các công cụ nhận dạng giọng nói của Azure Cognitive Services, vì vậy, một tổng đài viên được thông báo trước và sẵn sàng tham gia trước khi họ bắt đầu gọi. Tương tự, mọi thông tin nhận dạng có thể được chuyển giao cho Dynamics 365 để truy cập trực tiếp vào nội dung quản lý quan hệ khách hàng.
Đây có lẽ là lợi thế lớn nhất của việc sử dụng Dịch vụ Truyền thông Azure, khả năng tích hợp sâu của dịch vụ này với phần còn lại của nền tảng Azure và các đám mây khác của Microsoft. Bằng cách làm việc với mã của riêng bạn và các dịch vụ của Microsoft, thậm chí với các công cụ mã thấp của Power Platform, bạn có thể xây dựng các dịch vụ phức tạp hơn nhiều một cách nhanh chóng hơn.
NHÌN THẤY: Khám phá cách sử dụng công cụ mã thấp có thể giảm bớt khối lượng công việc cho nhóm CNTT của bạn.
Có một lợi thế khác khi sử dụng các công cụ này để xây dựng môi trường trung tâm cuộc gọi của riêng bạn. Bằng cách sử dụng quy trình làm việc để định tuyến cuộc gọi nội bộ qua Azure, bạn có thể cung cấp một số bên ngoài duy nhất cho các dịch vụ của mình và ẩn tất cả các số được cung cấp cho người điều hành và nhân viên khác, sử dụng cùng một số cho các cuộc gọi đi từ nền tảng dịch vụ khách hàng của bạn. Cung cấp quyền riêng tư cho nhân viên là rất quan trọng và việc sử dụng kỹ thuật này giúp duy trì quyền riêng tư trong khi vẫn cấp cho khách hàng quyền truy cập vào nền tảng hỗ trợ của bạn.
Microsoft tiếp tục mở rộng các API liên lạc của mình, cung cấp các công cụ cho các doanh nghiệp thuộc mọi quy mô sử dụng điện thoại được lưu trữ trên đám mây. Với khả năng tích hợp các tính năng như thế này với Teams, các ứng dụng thu được sẽ phù hợp gọn gàng với các quy trình kinh doanh hiện có mà không làm thay đổi đáng kể cách chúng ta làm việc.
Đọc tiếp: Những cải tiến trong kho lưu trữ dữ liệu dành cho Microsoft Dataverse nhằm mục đích giúp các doanh nghiệp xây dựng dựa trên dữ liệu của họ.
Không có gì giống như cơn sốt hoài cổ của những người máy cổ điển từ những năm 1980. Có vẻ như thế giới đang xôn xao với những giấc mơ về cách những sinh vật điện tử tương lai này sẽ hòa nhập vào xã hội của chúng ta. Bây giờ, nhờ điều này quả mâm xôi dự án của Matt từ Viam Robotics, cuối cùng chúng ta cũng có một trường hợp sử dụng mới cho một trong những rô bốt phổ biến nhất của thập niên 80, Tomi Omnibot 2000. Dự án này, được đặt tên là Omnibot MAIV, cập nhật robot cổ điển bằng Pi để thêm các tính năng mới do AI cung cấp.
Omnibot MAIV khai thác sức mạnh của Raspberry Pi đầy tiềm năng sáng tạo. Matt phác thảo một vài khả năng trong hướng dẫn của anh ấy, nhưng bạn có thể tạo lại dự án này ở nhà và sửa đổi nó bằng các tính năng mới của riêng bạn. Từ việc tích hợp AI đến các lệnh không dây, bầu trời là giới hạn—hoặc có thể chỉ là số lượng GPIO dự phòng mà bạn có cho các tiện ích bổ sung.
Tên mới, Ombinot MAIV, viết tắt của Ombinot Modernized with AI and Viam. Matt cố gắng giữ lại càng nhiều phần cứng ban đầu càng tốt trong khi thêm vào càng nhiều thứ mới càng tốt. Sáng tạo Ombinot MAIV của anh ấy có tuyển chọn các cảm biến mới, có thể sử dụng công nghệ máy học để tương tác với thế giới xung quanh và có thể truy cập từ xa qua kết nối an toàn.
Hình ảnh 1 của 3
(Nguồn: Matt, Viam)
(Nguồn: Matt, Viam)
(Nguồn: Matt, Viam)
Nếu bạn muốn xây dựng của riêng mình, bạn sẽ cần một chút phần cứng bao gồm cả Ombinot cũ. Matt xác nhận rằng bạn sẽ không cần một cái có điều khiển từ xa hoặc khay nhưng nó càng ở trong tình trạng tốt thì bạn càng ít phải làm. Anh ấy đã thêm một số đèn LED cho mắt cũng như một webcam để nhập video. Bất kỳ SBC nào có khả năng chạy Linux 64 bit đều hoạt động, trong trường hợp này, anh ấy đang sử dụng Raspberry Pi 4B. Tất cả mọi thứ được cung cấp bởi một bộ pin 12V.
Niềm vui thực sự bắt đầu khi bạn đào sâu vào khía cạnh phần mềm của mọi thứ. Đây là nơi bạn thực sự có thể điều khiển Omnibot MAIV với độ linh hoạt cao. Các tính năng mới thú vị được xử lý bằng Viam Server. Bạn có thể làm theo hướng dẫn của Matt để biết cách thiết lập các điều khiển bằng mắt, khả năng di chuyển cũng như đầu vào hình ảnh từ mũi webcam. Nhưng đừng để hướng dẫn giới hạn bạn, có rất nhiều thứ hay ho khác mà bạn có thể tự thêm vào. Matt gợi ý những thứ như phát hiện hoặc điều hướng đối tượng và màu sắc.
Nếu bạn muốn xem xét kỹ hơn về dự án Raspberry Pi này, hãy xem trang dự án và hướng dẫn do Matt tổng hợp trên trang web Viam.
Nhà vô địch chơi game Ryzen 9 7900X3D 12 nhân của AMD hiện đang được bán với giá chỉ 500 đô la trên Newegg. Thỏa thuận này được thực hiện bằng mã khuyến mãi 90 đô la, giảm giá của 7900X3D từ 589,99 đô la xuống còn 499,99 đô la. Trên hết, CPU vẫn đi kèm với Chiến tranh giữa các vì sao Jedi: Người sống sótgiúp người chơi tiết kiệm thêm $70.
Để có được ưu đãi đáng kinh ngạc này, tất cả những gì bạn cần làm là nhập mã khuyến mãi MDSCS2343 trong quá trình thanh toán.
Ryzen 9 7900X3D là một trong những CPU tốt nhất để chơi game, cung cấp tốc độ khung hình cao ngất ngưởng với sự tích hợp của công nghệ 3D-VCache thế hệ thứ hai của AMD. Trong bảng xếp hạng của chúng tôi, chip 12 nhân xếp ngay sau những người anh em 8 nhân và 16 nhân mạnh hơn của nó, đạt tổng thể 212 khung hình / giây ở 1080P. Mặc dù ở vị trí thứ ba, nhưng nó vẫn nhanh hơn tất cả các CPU tốt nhất của Intel, bao gồm cả Core i9-13900K.
Thông số kỹ thuật đầy đủ của CPU bao gồm 12 nhân, 24 luồng, xung nhịp cơ bản 4,4 GHz, xung nhịp tăng tốc 5,6 GHz và bộ nhớ đệm 140 MB kết hợp bộ nhớ đệm L2 12 MB và bộ nhớ đệm L3 128 MB. Việc bổ sung công nghệ 3D-VCache của AMD tăng gấp đôi dung lượng bộ nhớ đệm L3 của 7900X3D từ 64 MB lên 128 MB. Con chip này có xếp hạng TDP 120W, tuy nhiên, trong bài đánh giá của chúng tôi, chúng tôi thấy rằng con chip này tiêu thụ ít hơn 100W trong khối lượng công việc đa luồng đầy đủ, khiến con chip này trở thành một trong những CPU có số lượng lõi cao hiệu quả nhất trên thị trường.
Với giá 500 đô la, 7900X3D được cho là một trong những CPU dòng Ryzen 7000 tốt nhất dành cho người dùng thành thạo muốn chơi game và tận hưởng năng suất mà CPU Zen 4 12 nhân đa luồng có thể mang lại. Ở mức giá này, CPU chỉ cao hơn 50 đô la so với Ryzen 7 7800X3D và cung cấp hiệu năng chơi game gần như ngang bằng với bốn lõi và tám luồng nữa.
Có vẻ như MSI gần như đã sẵn sàng tung ổ SSD Spatium M570 Pro PCIe 5.0 ra khỏi cửa. Công ty cho biết họ sẽ trưng bày SSD tại gian hàng Computex ở Đài Bắc vào tuần tới. Lần đầu tiên chúng tôi nhìn thấy SSD vào đầu năm nay tại gian hàng CES của MSI, nơi nó đạt tốc độ đọc và ghi tuần tự lần lượt là 12.000 MBps và 10.000 MBps. Trong những tháng kể từ lần ra mắt đầu tiên đó, MSI đã có thể tăng hiệu suất để đưa nó vào danh sách các ổ SSD PCIe 5.0 nhanh nhất cho năm 2023.
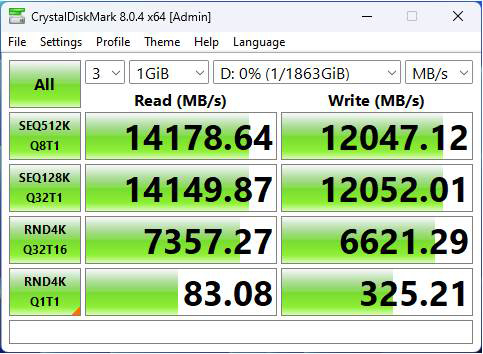
Điểm chuẩn hiệu suất mới nhất của MSI từ CrystalDiskMark cho thấy Spatium M570 Pro đạt gần 14.200 MBps trong các lần đọc tuần tự, trong khi ghi tuần tự chỉ đạt hơn 12.000 MBps. Điều đó đặt hiệu suất đọc hơi chậm hơn so với T-Force Z54A nhưng dẫn đầu về hiệu suất ghi. Tuy nhiên, chúng tôi phải lưu ý rằng hiệu suất SSD còn nhiều hơn tốc độ đọc/ghi tuần tự thô, nhưng MSI vẫn tỏ ra rất mạnh mẽ với mục mới này trong lĩnh vực SSD PCIe 5.0.
(Nguồn: MSI)
Spatium M570 Pro sử dụng bộ điều khiển Phison PS5026-E26 mà chúng tôi mong đợi sẽ thấy trong số lượng lớn các ổ SSD PCIe 5.0 được phát hành trong năm nay. T-Force Z54A nói trên đã sử dụng bộ điều khiển Innogrit IG5666. SSD cũng sử dụng NAND 232 lớp 2.400 tấn. Như với hầu hết mọi ổ SSD PCIe 5.0 mà chúng tôi đã thấy cho đến nay, M570 Pro có bộ tản nhiệt mạnh mẽ và một tấm buồng hơi để duy trì hiệu suất nhất quán khi chịu tải. Nếu không có giải pháp làm mát đầy đủ, SSD PCIe 5.0 rất dễ bị tiết lưu nhiệt, điều này giải thích cho các thiết lập phức tạp tại chỗ.
Spatium M570 kém hiệu suất hơn (10.000 MBps cho các lần đọc và ghi tuần tự) đã có sẵn từ các nhà bán lẻ với dung lượng 1TB và 2TB. Ví dụ: Spatium M570 2TB có giá 349,99 USD tại Newegg. Tuy nhiên, MSI vẫn chưa giải thích chi tiết về tính sẵn có của Spatium M570 Pro ngoài việc nói rằng nó sẽ có sẵn trong Quý 2, thời điểm sắp kết thúc.
Spatium M570 Pro sẽ có các mức dung lượng 1TB, 2TB và 4TB khi ra mắt và chúng tôi hy vọng rằng nó sẽ có mức giá cao hơn so với người anh em “không phải Pro” của nó.