
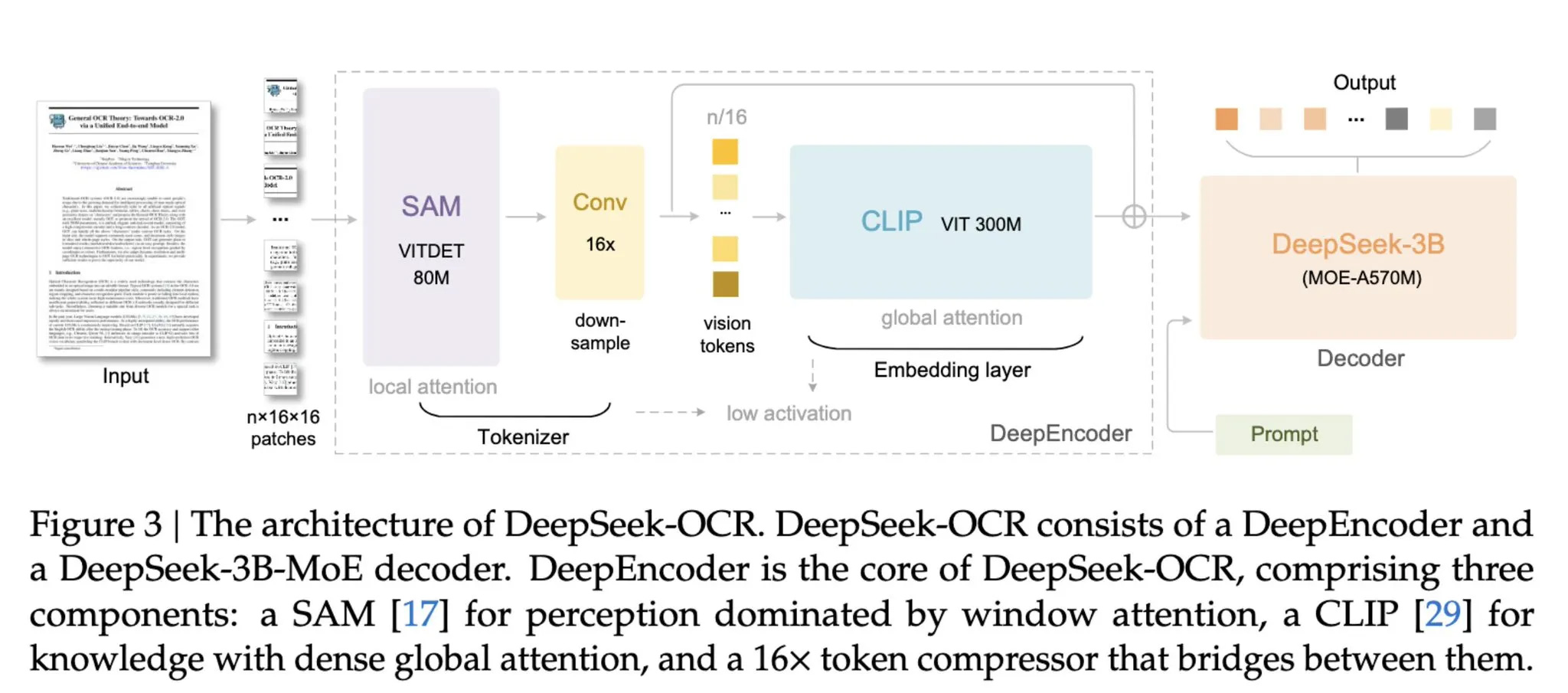
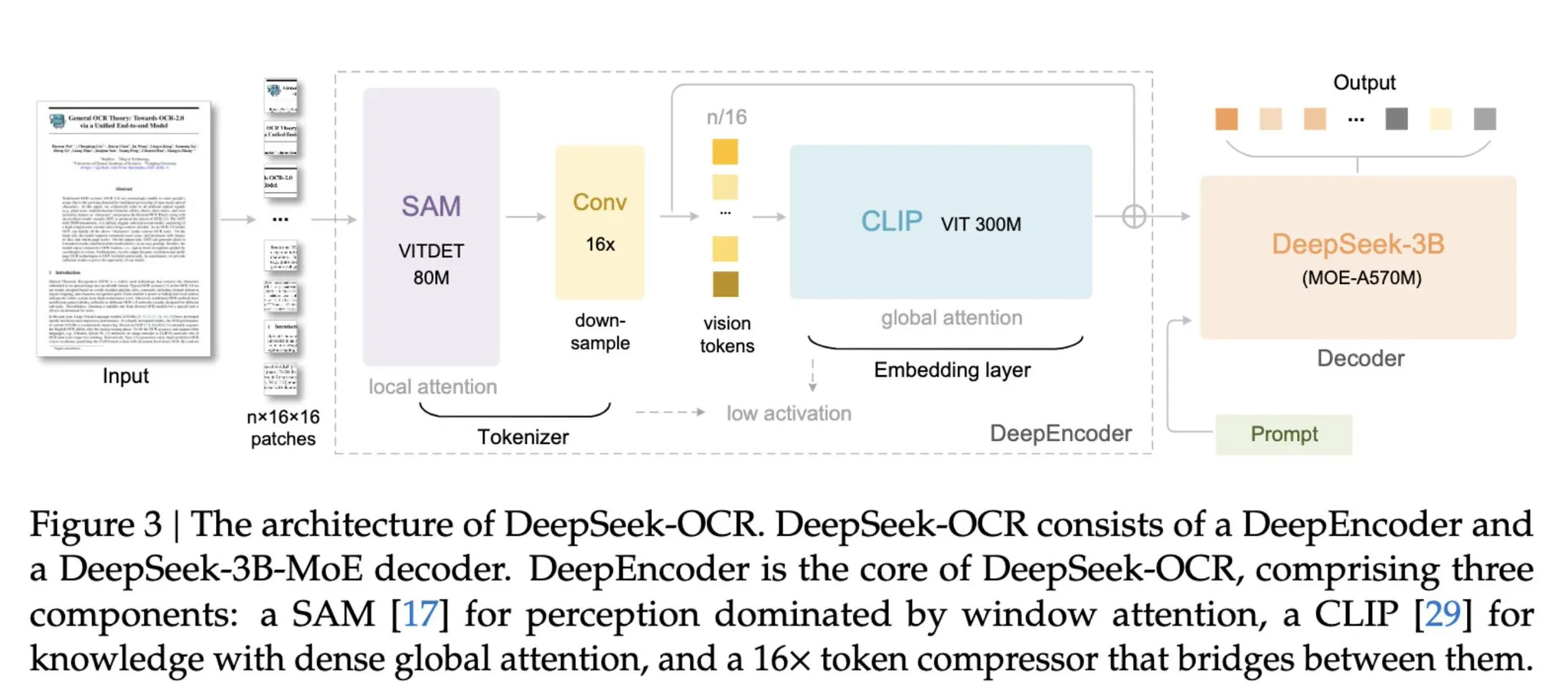
Các nhà phát triển Deepseek AI của Trung Quốc đã phát hành một mô hình mới tận dụng khả năng đa phương thức của nó để cải thiện hiệu quả xử lý các tài liệu phức tạp và khối văn bản lớn, bằng cách chuyển đổi chúng thành hình ảnh trước tiên, theo SCMP. Bộ mã hóa thị giác có thể lấy số lượng lớn văn bản và chuyển đổi chúng thành hình ảnh, khi truy cập sau này, yêu cầu số lượng mã thông báo ít hơn từ 7 đến 20 lần, trong khi vẫn duy trì mức độ chính xác ấn tượng.
Deepseek là AI do Trung Quốc phát triển đã gây chấn động thế giới vào đầu năm 2025, thể hiện các khả năng tương tự như ChatGPT của OpenAI hoặc Gemini của Google, mặc dù cần ít tiền và dữ liệu hơn để phát triển. Kể từ đó, những người sáng tạo đã tiếp tục nỗ lực làm cho AI hiệu quả hơn và với bản phát hành mới nhất có tên DeepSeek-OCR (nhận dạng ký tự quang học), AI có thể mang lại hiểu biết ấn tượng về số lượng lớn dữ liệu văn bản mà không cần sử dụng mã thông báo thông thường.
Nhà phát triển cho biết: “Thông qua DeepSeek-OCR, chúng tôi đã chứng minh rằng việc nén văn bản trực quan có thể giảm đáng kể mã thông báo – từ 7 đến 20 lần – cho các giai đoạn bối cảnh lịch sử khác nhau, đưa ra một hướng đi đầy hứa hẹn” để xử lý các tính toán theo ngữ cảnh dài.

Điều này hoạt động thực sự tốt để xử lý dữ liệu được lập bảng, biểu đồ và các cách trình bày thông tin trực quan khác. Các nhà phát triển đề xuất điều này có thể được sử dụng đặc biệt trong tài chính, khoa học hoặc y học.
Khi đo điểm chuẩn, các nhà phát triển khẳng định rằng khi giảm số lượng mã thông báo xuống dưới hệ số 10, DeepSeek-OCR có thể duy trì mức độ chính xác 97% khi giải mã thông tin. Nếu tăng tỷ lệ nén lên 20 lần thì độ chính xác giảm xuống còn 60%. Điều đó ít được mong muốn hơn và cho thấy lợi nhuận của công nghệ này đang giảm dần, nhưng nếu có thể đạt được tỷ lệ chính xác gần 100% với tốc độ nén thậm chí 1-2 lần, thì điều đó vẫn có thể tạo ra sự khác biệt lớn về chi phí chạy nhiều mô hình AI mới nhất.
Nó cũng được quảng cáo là một cách để phát triển dữ liệu huấn luyện cho các mô hình trong tương lai, mặc dù việc đưa ra các lỗi vào thời điểm đó, thậm chí ở dạng sai lệch vài phần trăm, có vẻ là một ý tưởng tồi.
Nếu bạn muốn tự mình thử nghiệm mô hình, nó có sẵn thông qua các nền tảng dành cho nhà phát triển trực tuyến ôm mặt Và GitHub.


Theo Phần cứng của Tom trên Google Tin tứchoặc thêm chúng tôi làm nguồn ưa thíchđể nhận tin tức, phân tích và đánh giá mới nhất của chúng tôi trong nguồn cấp dữ liệu của bạn.