AWS sử dụng Habana Gaudi của Intel cho các mô hình ngôn ngữ lớn
Mặc dù Habana Gaudi của Intel cung cấp hiệu suất cạnh tranh phần nào và đi kèm với gói phần mềm Habana SynapseAI, nhưng nó vẫn kém hơn so với GPU điện toán hỗ trợ CUDA của Nvidia. Điều này, kết hợp với tính khả dụng hạn chế, là lý do tại sao Gaudi không phổ biến đối với các mô hình ngôn ngữ lớn (LLM) như ChatGPT.
Giờ đây, khi cơn sốt AI đang bắt đầu, Habana của Intel đang được triển khai rộng rãi hơn. Amazon Web Services đã quyết định dùng thử Gaudi thế hệ thứ nhất của Intel với PyTorch và DeepSpeed để đào tạo LLM và kết quả đủ hứa hẹn để cung cấp các phiên bản DL1 EC2 trên thị trường.
Đào tạo các mô hình ngôn ngữ lớn (LLM) với hàng tỷ tham số đưa ra những thách thức. Họ cần các kỹ thuật đào tạo chuyên biệt, xem xét giới hạn bộ nhớ của một máy gia tốc duy nhất và khả năng mở rộng của nhiều máy gia tốc hoạt động đồng bộ. Các nhà nghiên cứu từ AWS đã sử dụng DeepSpeed, một thư viện tối ưu hóa deep learning mã nguồn mở dành cho PyTorch, được thiết kế để giảm thiểu một số thách thức trong quá trình đào tạo LLM, đồng thời đẩy nhanh quá trình đào tạo và phát triển mô hình, cũng như các phiên bản Amazon EC2 DL1 dựa trên Intel Habana Gaudi cho công việc của họ. Kết quả họ đạt được có vẻ rất hứa hẹn.
Các nhà nghiên cứu đã xây dựng một cụm điện toán được quản lý bằng AWS Batch, bao gồm 16 phiên bản dl1.24xlarge, mỗi phiên bản có tám bộ tăng tốc Habana Gaudi và 32 GB bộ nhớ cũng như mạng RoCE dạng lưới đầy đủ giữa các thẻ với tổng băng thông kết nối hai chiều mỗi thẻ là 700 Gbps. Ngoài ra, cụm này được trang bị bốn Bộ điều hợp vải đàn hồi AWS với tổng kết nối 400 Gbps giữa các nút.
Về khía cạnh phần mềm, các nhà nghiên cứu đã sử dụng tối ưu hóa DeepSpeed ZeRO1 để đào tạo trước mô hình BERT 1.5B với nhiều tham số khác nhau. Mục tiêu là để tối ưu hóa hiệu suất đào tạo và hiệu quả chi phí. Để đảm bảo sự hội tụ của mô hình, các siêu tham số đã được điều chỉnh và kích thước lô hiệu quả trên mỗi máy gia tốc được đặt thành 384, với các lô siêu nhỏ là 16 mỗi bước và 24 bước tích lũy độ dốc.
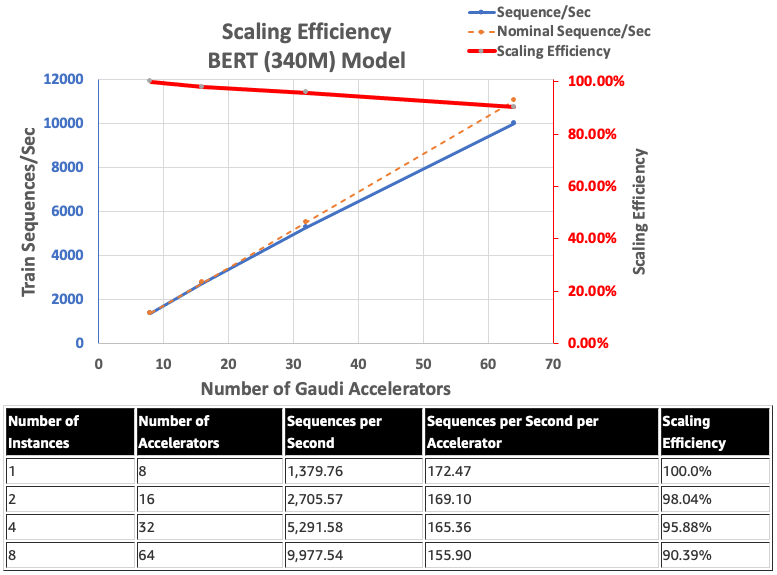
Hiệu suất mở rộng quy mô của Intel HabanaGaudi có xu hướng tương đối cao và không bao giờ giảm xuống dưới 90%, với tám phiên bản và 64 máy gia tốc chạy mô hình BERT 340 triệu.
Trong khi đó, bằng cách sử dụng hỗ trợ BF16 gốc của Gaudi, các nhà nghiên cứu AWS đã giảm các yêu cầu về kích thước bộ nhớ và tăng hiệu suất đào tạo so với FP32 để kích hoạt các mô hình BERT 1,5 tỷ. Họ đã đạt được hiệu suất mở rộng là 82,7% trên 128 máy gia tốc bằng cách sử dụng tối ưu hóa DeepSpeed Zero giai đoạn 1 cho mô hình BERT với 340 triệu đến 1,5 tỷ tham số.
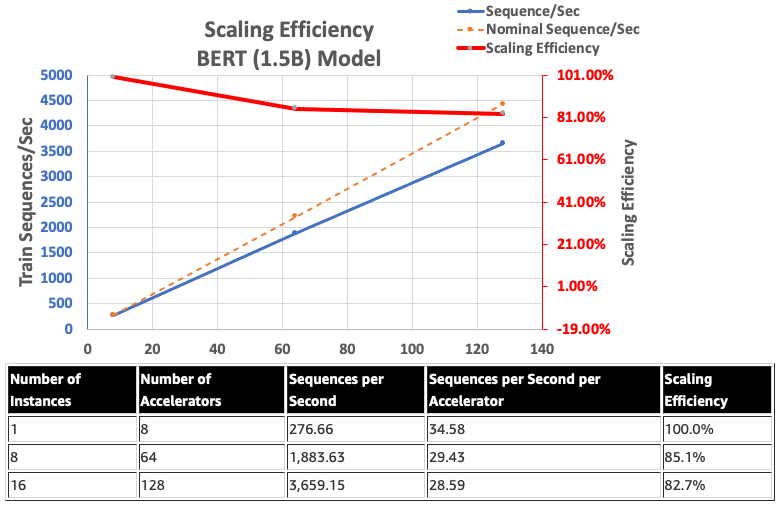
Nhìn chung, các nhà nghiên cứu của AWS nhận thấy rằng bằng cách sử dụng phần mềm Habana SynapseAI v1.5/v1.6 phù hợp với DeepSpeed và nhiều bộ gia tốc Habana Gaudi, một mô hình BERT với 1,5 tỷ tham số có thể được đào tạo trước trong vòng 16 giờ, đạt đến sự hội tụ trên mạng 128 Máy gia tốc Gaudi, đạt hiệu suất mở rộng 85%. Kiến trúc có thể được đánh giá trong Hội thảo AWS.