Ampere tiết lộ CPU 192 nhân, sau đó đưa ra kết quả thử nghiệm gây tranh cãi
Ampere tuần này đã giới thiệu bộ xử lý AmpereOne dành cho trung tâm dữ liệu đám mây, đây là CPU đa năng đầu tiên trong ngành có tới 132 CPU có thể được sử dụng để suy luận AI.
Các chip mới tiêu thụ nhiều năng lượng hơn so với các chip tiền nhiệm — Ampere Altra (sẽ duy trì trạng thái ổn định của Ampere trong ít nhất một thời gian) — nhưng công ty tuyên bố rằng mặc dù mức tiêu thụ điện năng cao hơn, bộ xử lý có tới 192 lõi của họ cung cấp mật độ tính toán cao hơn so với CPU từ AMD và Intel. Một số tuyên bố về hiệu suất đó có thể gây tranh cãi.
192 Lõi gốc đám mây tùy chỉnh
Bộ xử lý AmpereOne của Ampere có 136 – 192 lõi (trái ngược với 32 đến 128 lõi của Ampere Altra) chạy ở tốc độ lên tới 3,0 GHz dựa trên triển khai độc quyền của công ty về kiến trúc tập lệnh Armv8.6+ (có hai vectơ 128 bit đơn vị hỗ trợ các định dạng FP16, BF16, INT16 và INT8) được trang bị bộ nhớ đệm L2 kết hợp 8 chiều thiết lập 2 MB trên mỗi lõi (tăng từ 1 MB) và được kết nối với nhau bằng mạng mech với 64 nút nhà và rình mò dựa trên thư mục lọc. Ngoài bộ đệm L1 và L2, SoC còn có bộ đệm cấp hệ thống 64MB. Các CPU mới được đánh giá ở mức 200W – 350W tùy thuộc vào SKU chính xác, tăng từ 40W – 180W đối với Ampere Altra.

Công ty tuyên bố rằng các lõi mới của họ được tối ưu hóa hơn nữa cho khối lượng công việc trên đám mây và AI, đồng thời có các hướng dẫn ‘sức mạnh và hiệu quả’ trên mỗi lần tăng xung nhịp (IPC), điều này có thể có nghĩa là IPC cao hơn (so với Neoverse N1 của Arm được sử dụng cho Altra) mà không có sự gia tăng rõ rệt nào trong tiêu thụ điện năng và khu vực chết. Nói về diện tích khuôn, Ampere không tiết lộ nhưng nói rằng AmpereOne được sản xuất trên một trong những công nghệ xử lý cấp 5nm của TSMC.
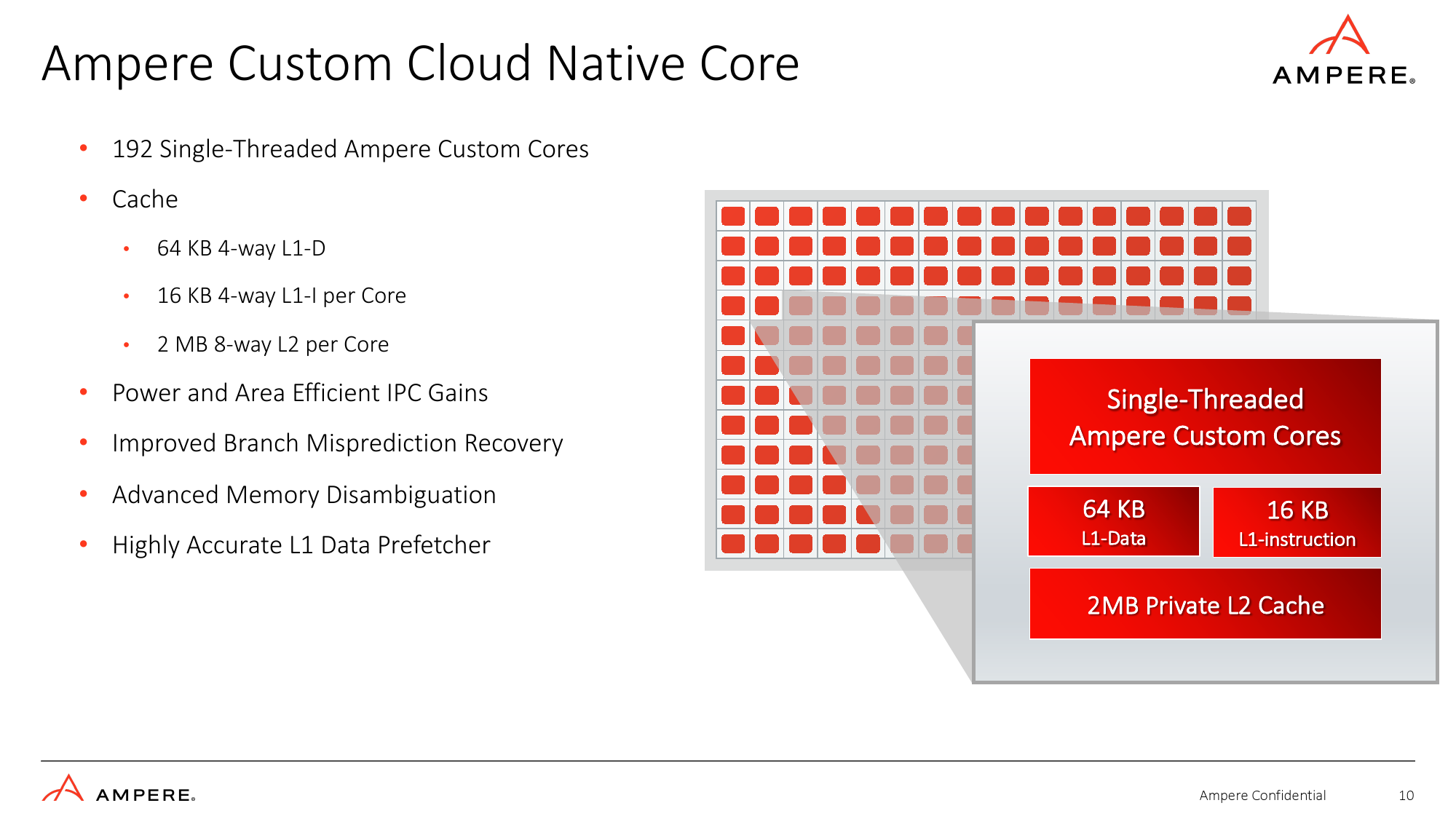
Mặc dù Ampere không tiết lộ tất cả các chi tiết về lõi AmpereOne của nó, nhưng nó nói rằng chúng có tính năng tìm nạp trước dữ liệu L1 có độ chính xác cao (giảm độ trễ, đảm bảo rằng CPU dành ít thời gian chờ dữ liệu hơn và giảm mức tiêu thụ năng lượng của hệ thống bằng cách giảm thiểu truy cập bộ nhớ), khôi phục dự đoán sai nhánh được tinh chỉnh (CPU có thể phát hiện dự đoán sai nhánh và khôi phục càng sớm, nó sẽ giảm độ trễ và sẽ tốn ít năng lượng hơn) và phân định bộ nhớ tinh vi (tăng IPC, giảm thiểu tắc nghẽn đường ống, tối đa hóa việc thực thi không theo thứ tự, giảm độ trễ và cải thiện khả năng xử lý nhiều yêu cầu đọc/ghi trong môi trường ảo hóa).
Mặc dù danh sách các cải tiến kiến trúc lõi của AmpereOne có vẻ không quá dài trên giấy, nhưng những điều này thực sự có thể cải thiện hiệu suất đáng kể và chúng cần thực hiện rất nhiều nghiên cứu (tức là điều gì làm chậm hiệu suất của CPU trung tâm dữ liệu đám mây nhất?) và rất nhiều công việc để thực hiện chúng một cách hiệu quả.
Bảo mật nâng cao và I/O
Do AmpereOne SoC hướng đến các trung tâm dữ liệu đám mây nên nó được trang bị I/O phù hợp, bao gồm tám kênh DDR5 cho tối đa 16 mô-đun hỗ trợ bộ nhớ lên đến 8TB trên mỗi ổ cắm, 128 làn PCIe Gen5 với 32 bộ điều khiển và phân nhánh x4.
Trung tâm dữ liệu cũng yêu cầu độ tin cậy, tính khả dụng, khả năng bảo trì (RAS) và các tính năng bảo mật nhất định. Cuối cùng, SoC hỗ trợ đầy đủ bộ nhớ ECC, mã hóa bộ nhớ khóa đơn, gắn thẻ bộ nhớ, ảo hóa an toàn và ảo hóa lồng nhau, chỉ để nêu tên một vài trong số chúng. Ngoài ra, AmpereOne còn có nhiều khả năng bảo mật như bộ tăng tốc mã hóa và entropy, giảm thiểu tấn công kênh đầu cơ, giảm thiểu tấn công ROP/JOP, v.v.
Kết quả điểm chuẩn tò mò
Không còn nghi ngờ gì nữa, AmpereOne SoC của Ampere là một miếng silicon ấn tượng được thiết kế để xử lý khối lượng công việc trên đám mây và có 192 lõi đa năng, lần đầu tiên trong ngành. Tuy nhiên, để chứng minh quan điểm của mình, Ampere sử dụng kết quả điểm chuẩn khá kỳ lạ.
Ampere coi mật độ tính toán của AmpereOne là lợi thế chính của nó. Công ty tuyên bố rằng một giá đỡ 42U 16,5kW chứa đầy các máy 1S dựa trên AmpereOne SoC 192 lõi có thể hỗ trợ tới 7926 máy ảo, trong khi một giá đỡ dựa trên EPYC 9654 ‘Genoa’ 96 lõi của AMD có thể xử lý 2496 máy ảo và một giá đỡ được hỗ trợ bởi CPU Xeon 8480+ ‘Sapphire Rapids’ có thể mở rộng 56 lõi của Intel có thể xử lý 1680 máy ảo. Sự so sánh này rất có ý nghĩa trong ngân sách điện năng 16,5kW.
Hình ảnh 1 của 2

Tuy nhiên, mật độ năng lượng của giá đỡ 42U đang tăng lên và các công cụ exascaler như AWS, Google và Microsoft đã sẵn sàng cho điều này, đặc biệt là đối với khối lượng công việc đòi hỏi hiệu năng cao của họ. Dựa trên một cuộc khảo sát từ UpTimeInstolarship vào năm 2020, chúng tôi có thể nói rằng 16% công ty đã triển khai các rakc 42U điển hình với mật độ công suất trên giá đỡ từ 20kW đến hơn 50kW. Cho đến nay, số lượng triển khai điển hình với giá đỡ 20kW đã tăng chứ không giảm, vì các CPU thế hệ trước và mới nhất của AMD đã tăng TDP so với các thế hệ trước.
Hình ảnh 1 của 2
Khi nói đến hiệu suất, Ampere thể hiện những ưu điểm của hệ thống dựa trên AmpereOne 160 lõi với bộ nhớ 512GB chạy Generative AI (khuếch tán ổn định) và AI Recommenders (DLRM) so với các hệ thống dựa trên CPU EPYC 9654 96 lõi của AMD với 256GB dung lượng lưu trữ. bộ nhớ (có nghĩa là nó hoạt động ở chế độ tám kênh, không phải chế độ 12 kênh được Genoa hỗ trợ). Các máy dựa trên ampe đã tạo ra số khung hình/giây nhiều hơn 2,3 lần đối với AI tổng quát và hơn 2 lần số truy vấn/giây đối với các đề xuất AI.
Trong trường hợp này, Ampere đã so sánh hiệu suất xử lý dữ liệu của các hệ thống của mình với độ chính xác FP16, trong khi các máy dựa trên AMD được tính toán với độ chính xác FP32, đây không phải là phép so sánh táo với táo. Hơn nữa, nhiều khối lượng công việc FP16 hiện đang chạy trên GPU thay vì trên CPU và GPU song song lớn có xu hướng mang lại kết quả ngoạn mục với khối lượng công việc đề xuất AI và AI tổng quát.
Bản tóm tắt
AmpereOne của Ampere là CPU đa năng đầu tiên trong ngành có tới 192 lõi, điều này chắc chắn xứng đáng nhận được nhiều sự tôn trọng. Các CPU này cũng có các khả năng I/O mạnh mẽ, các tính năng bảo mật nâng cao và hứa hẹn cải thiện hướng dẫn trên mỗi lần tăng xung nhịp (IPC). Ngoài ra, chúng có thể chạy khối lượng công việc AI với độ chính xác FP16, BF16, FP8 và INT8.
Nhưng công ty đã chọn sử dụng các phương pháp khá gây tranh cãi để chứng minh quan điểm của mình khi nói đến kết quả điểm chuẩn, điều này phủ bóng đen lên thành tích của họ. Điều đó nói rằng, sẽ rất thú vị khi xem kết quả kiểm tra độc lập của các máy chủ dựa trên AmpereOne.